
NVIDIA TEE GPU H200 Delivers High Performance for Decentrazlied AI
2024-10-31

In a recent study by Phala Network, io.net, and Engage Stack, the performance impact of enabling TEE on NVIDIA H100 and H200 Hopper GPUs was examined for large language model (LLM) inference tasks: https://arxiv.org/abs/2409.03992
TEEs add a security layer by isolating computations to protect sensitive data, which is essential for high-stakes applications. The findings highlight how TEE mode affects the H100 and H200 GPUs differently, revealing TEE's feasibility for secure, high-performance AI.
Key Findings
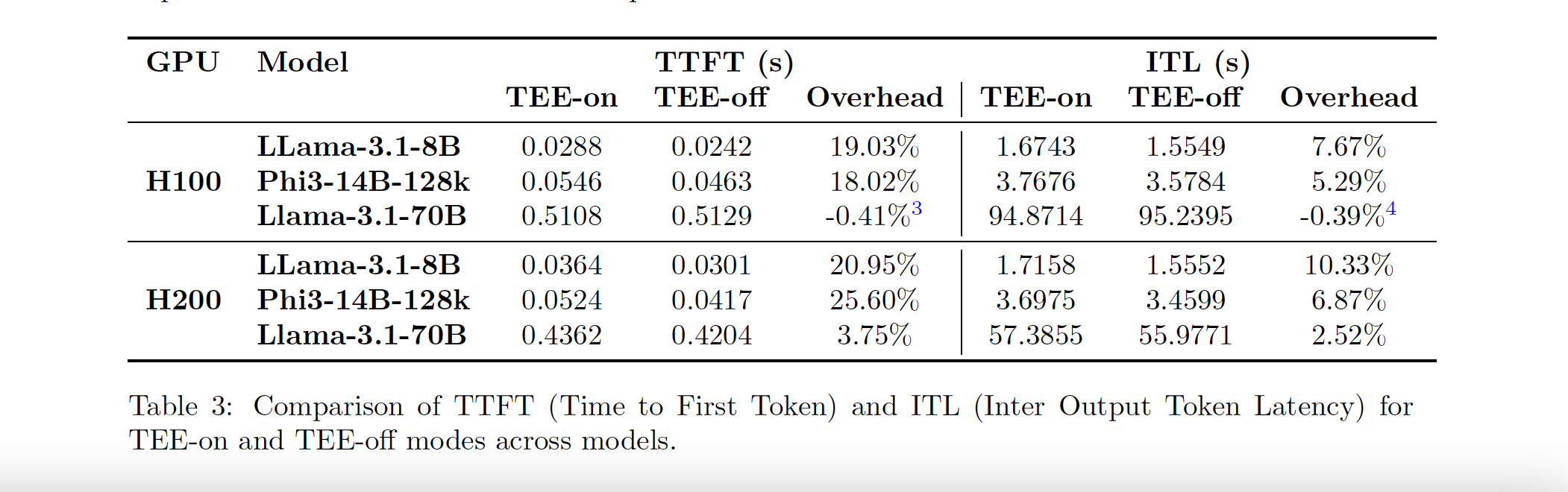
TEE-on mode has a greater impact on Time To First Token (TTFL) and Inter-Token Latency (ITL) in H200 compared to H100.
1 ) Minimal Impact on Core GPU Computation
TEE mode introduces only a minor impact on the GPUs' core computations, with the main performance bottleneck stemming from data transfer between the CPU and GPU. The additional encryption over PCIe channels—needed to maintain secure data flow—slightly raises latency, but the impact is contained. Both H100 and H200 GPUs demonstrated that minimizing data movement significantly reduces TEE overhead, helping maintain overall system efficiency.
2 ) Low Overhead for Most LLM Queries
For typical LLM tasks, TEE incurs under 7% performance overhead on both GPUs. As sequence length increases, this overhead decreases even further, becoming nearly negligible for extended inputs and outputs. This shows that TEE’s security layer can handle large-scale LLM tasks efficiently on both the H100 and H200, offering dependable security with minimal performance impact across most queries.
3 ) Positive Results Across Different Models and GPUs
Larger LLMs, such as Llama-3.1-70B, showed almost no performance penalty from TEE on either GPU, while smaller models like Llama-3.1-8B experienced a slightly higher impact. The H100 consistently outperformed the H200 in terms of overhead reduction, particularly with larger models. For example, Llama-3.1-70B incurred only a 0.13% overhead on the H100, while the H200 had a slightly higher 2.29% overhead. These results suggest that, while both GPUs are well-suited to high-demand applications, the H100 may be preferable for tasks requiring lower latency.
4 ) Minimal Real-Time Processing Impact
Real-time metrics such as Time to First Token (TTFT) and Inter-Token Latency (ITL) were used to evaluate latency. Both GPUs experienced minor latency increases in TEE mode, with the H200 displaying slightly higher overheads. However, as model size and sequence length grew, these latency effects diminished. The Llama-3.1-70B model, for instance, saw a TTFT overhead of -0.41% on the H100 and 3.75% on the H200. This indicates that TEE mode remains suitable for real-time applications, especially for larger, computation-intensive models where latency becomes less of a limiting factor.
5 ) High Throughput and Load Capacity for Secure AI Queries
Both TEE-enabled GPUs demonstrated substantial throughput and query load capacity, achieving nearly 130 tokens per second (TPS) on medium-sized inputs with the H100, while the H200 achieved comparably high TPS and QPS. Engage Stack’s cloud infrastructure was crucial in assessing these real-world, high-query load scenarios, affirming the H100 and H200’s capabilities in handling secure AI processing without significant bottlenecks.
Model Comparison and Main Takeaways
Across different models and workloads, the study underscores that TEE’s impact on performance remains under 7% for typical LLM tasks. Larger models, particularly with longer sequences, saw the TEE-related overhead diminish to nearly zero. For instance, the largest model tested, Llama-3.1-70B, displayed negligible performance impact, reinforcing TEE’s applicability for large-scale, sensitive applications. The study found that, despite the H200 experiencing slightly higher overhead than the H100, both GPUs maintained robust performance under TEE.
This distinction between the H100 and H200 results suggests that the H100 may be better suited for highly latency-sensitive applications, while the H200 remains a strong choice for secure, high-performance computing where the emphasis is on query load and large model processing.
Practical Implications for AI Using TEE
The findings confirm that TEE-enabled NVIDIA Hopper GPUs are effective for organizations prioritizing data security alongside computational efficiency. TEE mode proves manageable even for real-time applications, particularly on the H100, which manages latency effectively. With Engage Stack’s essential support, this research affirms that TEE can protect sensitive data without sacrificing scalability or throughput, especially for applications in sectors like finance, healthcare, and decentralized AI.
Conclusion
As the need for secure data handling grows, TEE-enabled NVIDIA H100 and H200 Hopper GPUs provide both security and efficiency, especially for complex LLM workloads. While the H200 exhibits a slightly higher performance overhead, both GPUs demonstrate that TEE can be implemented effectively without compromising throughput, particularly as model size and token lengths increase. This research validates the use of TEE in real-world, high-performance AI applications across fields that demand both confidentiality and processing power, supporting the broader adoption of secure, decentralized AI.
For more in-depth information visit the benchmark research.
