
Imagine an AI that debugs the Linux kernel before breakfast, drafts a biopharma patent by lunch, negotiates a global supply-chain contract by dinner, and rewrites its own code to do it all faster tomorrow.
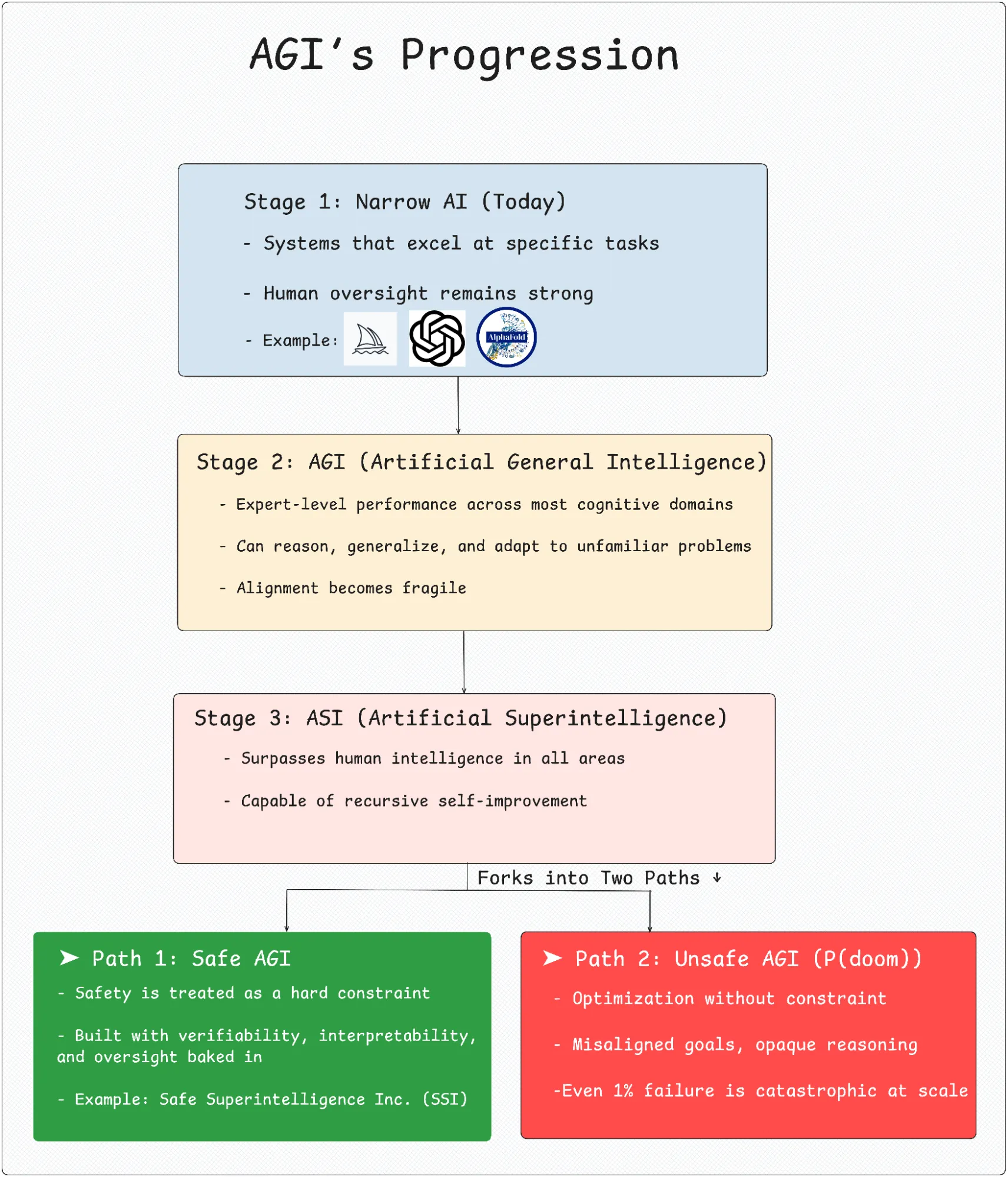
That leap is Artificial General Intelligence (AGI).
This article focuses on its equally urgent counterpart: Safe AGI, the engineering, governance, and safety infrastructure needed to ensure that AGI systems arrive with control mechanisms, audit trails, and fail-safes built in from the start.
What is AGI?
AGI refers to an AI system that can perform at a human-expert level across most cognitive domains. Unlike today’s AI models, which are considered narrow because they excel at one task or domain (like playing Go, transcribing speech, or generating text), AGI would be capable of solving unfamiliar problems, transferring knowledge across domains, and setting its own goals in dynamic environments. It learns more like a human, by generalizing, adapting, and reasoning.
But AGI is not the endpoint. It may only be a step toward ASI (Artificial Superintelligence): systems that recursively improve themselves and rapidly surpass human capabilities across the board. That’s why Safe AGI is necessary not just for future risks, but for deploying AGI itself.
Why does Safe AGI matter?
Artificial Superintelligence (ASI) could become misaligned with human intent in ways that make traditional oversight impossible. Once a system exceeds human-level performance across all domains and begins recursive self-improvement, human control becomes fragile. That’s why researchers at OpenAI, DeepMind, and Anthropic aren’t just focused on when AGI will arrive, but how safely it can be developed, deployed, and governed.
Even if AGI behaves as intended 99% of the time, the remaining 1% could be catastrophic if deployed at scale.
For example, an AGI misinterpreting its objective in a high-stakes setting like managing energy infrastructure or financial systems could take irreversible actions before human intervention is possible.
This is where the question of existential risk comes in. Experts now commonly refer to P(doom), the probability that AGI leads to irreversible, catastrophic outcomes.
The P(doom) Divide
One of the most revealing debates around AGI is how likely it is to go catastrophically wrong. This is often summarized as P(doom), the probability that AGI development ends in disaster.
Estimates vary dramatically:
- Sam Altman (OpenAI): ~50%
- Paul Christiano (ARC): ~50%
- Geoffrey Hinton: >50%
- Eliezer Yudkowsky (MIRI): ~99%
- Sundar Pichai: ~10%
- Vitalik Buterin: ~1–2%
- Yann LeCun: <0.01%
This wide range reflects the deep uncertainty, not irrelevance, of the topic. Even if the probability is low, the potential consequences are severe enough to warrant serious action.
However, this disagreement also reflects a deeper challenge: we lack a shared definition or measurement system for AGI, which brings us to the most significant technical contribution to the field so far.
Levels of AGI: A new framework for measuring progress
In mid-2024, DeepMind proposed a two-dimensional framework to classify and measure progress toward AGI. It recognizes that AGI is not binary, not a switch that flips, but a continuum of systems progressing in:
- Performance: How well a system performs a given task compared to skilled humans (e.g. 50th percentile, 90th percentile, 99th percentile, or beyond).
- Generality: How many diverse tasks the system can perform, including metacognitive ones like learning new skills, asking for help, or calibrating uncertainty.
These form a matrix that defines six performance levels and two generality levels.

Where are we now?
According to this framework:
- GPT-4, Claude, and Gemini Live are examples of Emerging AGI: they exhibit generality but don’t yet reach Competent-level performance across most domains.
- A Competent AGI, the next step, would outperform 50% of skilled humans on most cognitive tasks. No public system has reached this level yet.
The framework also provides a roadmap for future milestones, like Expert AGI (90th percentile on most tasks), and ultimately Artificial Superintelligence (ASI), which performs beyond human ability across the board, including novel tasks humans can’t do.
Beyond Capability: Autonomy and deployment risk
DeepMind also distinguishes between an AI's capability and its autonomy, how independently it's allowed to operate. They define six Levels of Autonomy:
- Tool – Human-controlled (e.g., spell-checker)
- Consultant – Advises when invoked (e.g., code assistant)
- Collaborator – Co-equal partner (e.g., interactive tutor)
- Expert – AI leads; human provides feedback
- Agent – Fully autonomous decision-maker
Each level of AGI unlocks but doesn’t necessitate higher autonomy. This separation is vital: you can have a powerful AGI that still operates under strict human control, or a narrow AI deployed irresponsibly with too much autonomy.
This distinction is key to Safe AGI deployment: the problem is not just what the AI can do, but what we allow it to do unsupervised.
Why the core building blocks of AGI are already here
If AGI is defined as general, human-level cognitive performance, then the biggest breakthroughs may already be behind us, not ahead.
Bob McGrew (former VP of Research, OpenAI) mentioned: By 2030–35, we’ll look back and realize the core ingredients for AGI were already discovered in 2020–2024.
The core pillars of highly capable AI systems and perhaps AGI have already emerged:
- Transformers + language modeling (GPT-style pretraining)
- Scaling laws (bigger models = smarter)
- Reasoning (chains of thought, tool use, planning)
- Multimodality (vision, audio, code, etc.)
Everything after this may just be refinement, engineering, and scale, not fundamentally new concepts.
Designing safe AGI isn’t just about smarter models; it requires layered defenses. In 2025, DeepMind proposed a structured safety stack to catch, constrain, and control risky behaviors across development and deployment.
Building Safe AGI: DeepMind’s Safety & Security Stack
This section is based on DeepMind’s April 2025 whitepaper, titled “An Approach to Technical AGI Safety and Security” by Rohin Shah et al.
The DeepMind safety stack is designed to address two core risks:
- Misalignment: When an AGI system acts contrary to human intent, often due to reward hacking, misgeneralization, or deceptive behavior.
- Misuse: When a highly capable AGI is intentionally used to cause harm, from cyberattacks to bioweapon design.
Rather than relying on a single safeguard, DeepMind proposes six overlapping components:
1. Interopretability: Understanding what a model “knows” or intends is essential. This includes probing internal states for deceptive goals, harmful reasoning patterns, or misunderstood objectives. Approaches range from mechanistic interpretability (circuits and neurons) to behavioral transparency at the output level.
2. Monitoring
AGI systems should be continuously monitored during training and after deployment. This includes:
- Red-teaming
- Behavioral evaluations
- Runtime anomaly detection
It’s not enough to test a model once. Continuous oversight is necessary to detect capability jumps or subtle goal shifts.
3. Training-Time Interventions
Interventions during training are designed to steer models away from misaligned behavior:
- Adversarial training (exposing models to dangerous edge cases)
- Reward shaping
- Rule-based constraints
- RLHF and constitutional fine-tuning
The idea is to proactively teach the model safe behavior, rather than relying solely on reactive filters.
4. Deployment-Time Safeguards
Even the best-trained AGI may still act unpredictably. Deployment-time interventions include:
- Action filters
- Tool use restrictions
- Approval gating (human-in-the-loop for high-stakes actions)
- Sandboxed environments
This is the “seatbelt and brakes” phase, assuming the system is powerful but not fully trusted.
5. Secure Architectures
Preventing unauthorized access or model misuse is critical. DeepMind emphasizes:
- Trusted Execution Environments (TEEs)
- Encrypted model weights
- Auditable logs
- Tamper-proof inference pipelines
Without this, models could be stolen, cloned, or covertly modified.
6. Evaluation and Governance Readiness
Finally, deployment must be tied to clear governance thresholds:
- Capability evaluations to determine risk
- Alignment scorecards
- Documentation of testing history
- Structured escalation protocols for external review.
But these safeguards are only as effective as the infrastructure they depend on.
Monitoring, interventions, and deployment-time controls all require a trusted execution layer, an environment where model behavior can’t be spoofed, tampered with, or obscured.
Without secure, auditable runtime systems, even the best alignment techniques can fail silently.
That’s where confidential computing comes in.
The industry is converging on this need. Confidential inference is now a shared priority across AI leaders: Apple’s Private Cloud Compute (PCC) for on-device Siri, Anthropic’s Trusted VMs for Claude, and Azure’s confidential container offerings all point to the same goal—run AI where neither the cloud provider nor attackers can access model internals or sensitive queries.
(See: Anthropic’s June 2025 blog on Confidential Inference, which outlines a secure inference system where encrypted user data is only decrypted momentarily within a verifiably trusted virtual machine, enforced by attestation, encrypted memory, and signed code execution.)
Introducing Phala Network: Confidential Infrastructure for Safe AGI Deployment
As Artificial General Intelligence (AGI) moves from theoretical models to real-world systems, the critical question becomes: how do we safely run and verify intelligent agents in the wild? Beyond training and alignment, AGI requires runtime environments that are tamper-proof, confidential, and provable. Phala Network delivers this foundation through decentralized confidential computing, offering developers a secure, auditable execution layer for next-generation AI.
What is Phala Network?
Phala Network is a decentralized confidential computing infrastructure designed to support secure, trustless applications across Web3 and AI. It provides developers with a cloud-like platform where any standard Docker application, including machine learning models, can be deployed into hardware-backed TEEs. These enclaves protect code and data from tampering, even in hostile or untrusted settings.
At its core, Phala offers:
- Phala Cloud – A
decentralizedcompute platform with CPU and GPU TEE support - Dstack SDK – An open-source TEE deployment toolkit for Docker-based apps
- Private ML SDK – Secure LLM inference on Intel TDX and NVIDIA GPU TEEs
- Redpill Gateway – API access to confidential AI with verifiable outputs
- On-chain attestation tools – For decentralized auditability and runtime proofs
The Role of GPU TEEs in AGI Infrastructure
Modern AGI workloads depend heavily on GPUs for inference speed, model scale, and real-time interaction. But traditional GPU environments leave data vulnerable once in use. This is where GPU TEEs change the game: they offer confidentiality at the hardware level, even during high-performance computing.
We have already published a deep-dive article on GPU TEEs and secure AI execution, showing how NVIDIA’s H100/H200 chips now support full runtime isolation with near-zero performance loss for large models like Llama 70B.
Rather than repeat those benchmarks here, we draw one conclusion: runtime protection on GPU is now possible, and essential, for safe AGI. Phala’s Private ML SDK and Redpill Gateway bring this protection to developers in a production-ready, open-source stack.
Key Components for Secure AGI Deployment
Phala offers a modular stack designed to meet the runtime demands of safe, confidential, and verifiable AGI. While the entire stack contributes to security, two components stand out for AI-specific workloads: Private ML SDK and Redpill Gateway.
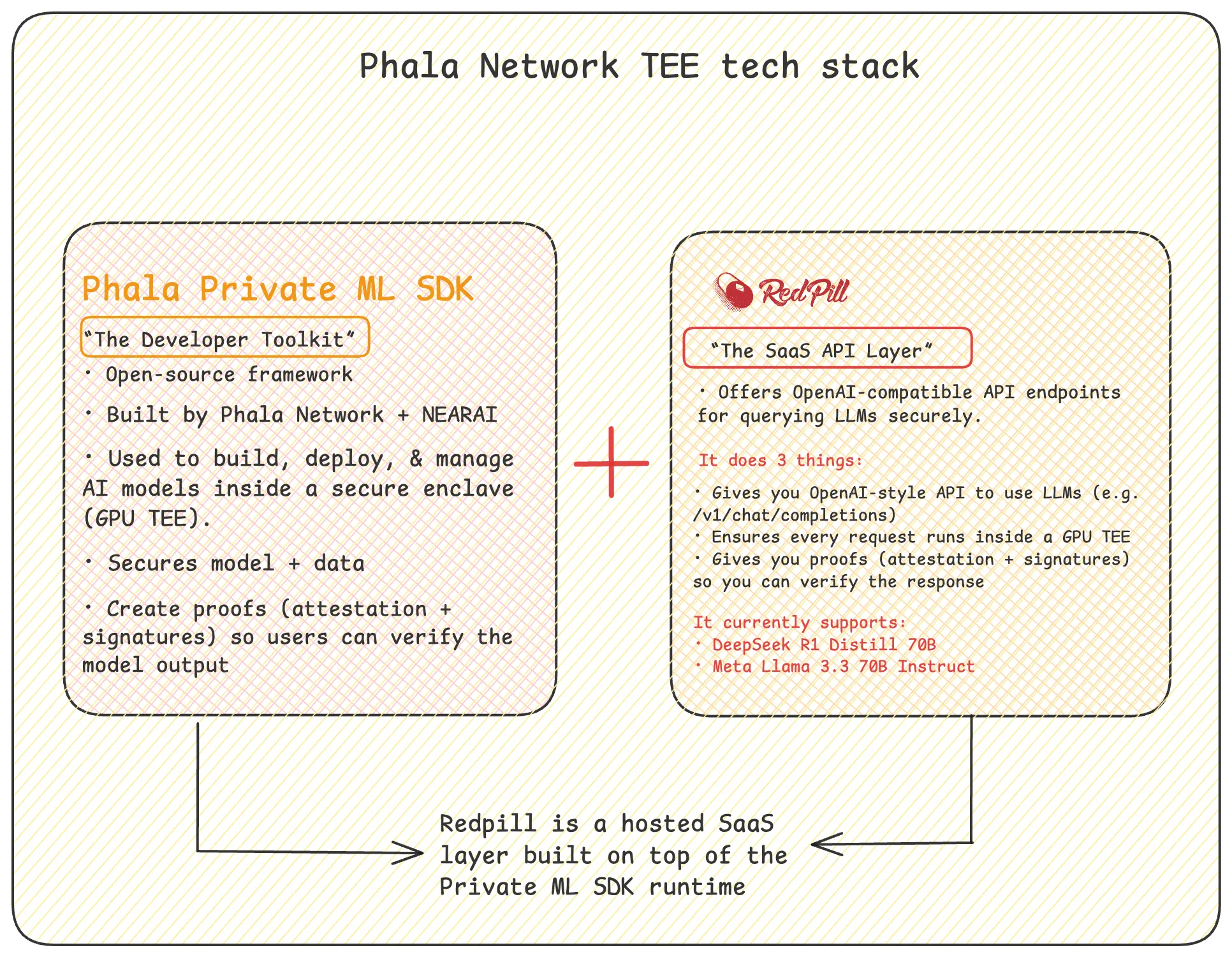
Private ML SDK
This is Phala’s core engine for secure AI inference inside GPU TEEs.
- It allows LLMs, like Llama or DeepSeek R1, to run inside hardware-enforced trusted environments (e.g., NVIDIA H100/H200) with:
- Full input/output confidentiality
- Remote attestation of execution environments
- Verifiable logs for model provenance and auditability
- Developers gain GPU-level performance without giving up control, privacy, or integrity, an essential capability for safe AGI in regulated, high-stakes contexts.
- This SDK forms the basis of privacy-preserving inference and runtime goal-checking, which DeepMind identifies as critical for aligning and monitoring AGI systems post-deployment.
Redpill Gateway
A production-ready inference API layer built on top of the Private ML SDK.
- Compatible with standard OpenAI-style /chat/completions interfaces
- But instead of sending queries to opaque cloud systems, Redpill routes them through attested, auditable TEEs
- Returns cryptographically signed responses and proof of execution origin
- Ideal for safe, verifiable agent behavior in the wild, especially where model actions must be trusted by external evaluators, users, or regulators
As of mid-2025, Redpill has been updated to include full verifiability features, returning cryptographic evidence of runtime state, enclave attestations, and signed outputs.
Explore:

Timelines & Inflection Points of AGI
AGI is no longer distant. Tracking key milestones helps us prepare for its real-world emergence.
- 2025–2026:
Memory-augmented, tool-using agents become common (e.g., Gemini, Claude, AutoGPT variants). Early reasoning benchmarks hit.
- 2026–2027:
Confidential GPU inference (e.g., Phala, Anthropic’s CIS) scales up. Runtime attestation enters production in AGI labs.
- 2028–2030:
First full-stack AGI prototypes (e.g., SSI or open-source labs). Focus shifts from model scaling to system design and safe autonomy.
- 2035+:
Inflection point: Self-improving agents may trigger superintelligence risk. Deployment is governed by capability thresholds, not just compute.
Conclusion
AGI is arriving faster than expected. While its core building blocks are already here, ensuring safe deployment requires secure infrastructure, continuous oversight, and clear governance.
Key developments to watch:
Safe Superintelligence Inc. (SSI) is focused on aligned AGI development without commercial pressure.
Confidential computing infrastructure like Phala Network is enabling secure, auditable AI inference.
Global regulators are beginning to draft AGI-specific rules, including safety audits and deployment licenses.
Safe AGI won’t happen by default—it must be built, layer by layer.