
This year, AI has become the defining narrative in Web3, powering everything from LLM-based agents to real-time trading bots. But AI doesn’t run on CPUs. It runs on GPUs.
Training a transformer model on CPUs would take weeks; GPUs accomplish the same in hours. For AI applications requiring real-time inference and training, GPUs are mandatory.
By 2030, over 70% of new capacity is expected to be “GPU-class,” dominated by accelerators like NVIDIA’s H100. These chips unlock massive parallelism for model training and inference, but come with a major blind spot: once data is in use on the GPU, it’s no longer protected.
Traditional encryption only protects data at rest and in transit, not while it’s being actively computed. Once decrypted inside a GPU’s memory, sensitive inputs, model weights, and outputs are vulnerable to:
- Malicious hypervisors
- Rogue admins with privileged access
- PCIe or NVLink snooping during CPU-GPU data transfer
- Attackers alter or censor model responses in real time.
GPU TEEs fix this by bringing confidential computing directly into the GPU itself.
What Is a GPU TEE?
A GPU Trusted Execution Environment (TEE) is a hardware-isolated enclave inside the GPU that protects code and data during execution. Even if the host OS or hypervisor is compromised, the workload running on the GPU remains secure, confidential, and tamper-proof.
GPU TEEs bring three key security pillars into the accelerator layer:
- Confidentiality: Keeps data hidden from unauthorized access during processing.
- Integrity: Ensures code and data aren’t tampered with during execution.
- Attestation: Proves the system is genuine and operating in a trusted state.
Modern implementations whether Nvidia’s CC-On, AMD’s Infinity Guard, or Intel’s forthcoming TDX Connect activate these protections automatically, yet preserve near-native performance (sub-2 % overhead on large Llama-class models).
Benchmarks from 2024 show H100 GPUs achieve near-zero performance overhead for large models like Llama-3.1-70B when using TEEs, making them ideal for secure AI in applications
CPU TEE vs GPU TEE
CPU TEEs (like Intel SGX, AMD SEV, and Intel TDX) were built for general-purpose compute and have long protected sensitive workloads in trusted enclaves.But they aren’t built for deep learning scale.
Large models like Llama-3 or Mixtral require thousands of parallel threads, high-throughput tensor operations, and massive memory bandwidth demands that exceed what CPU TEEs were designed for.
That’s where GPU TEEs come in by combining the computational power of accelerators with the security guarantees of confidential computing.Secure AI Needs Both CPU + GPU TEEs
Together with CPU TEEs, they form a layered trust foundation:
- CPU TEE boots the confidential VM, handles OS and drivers.
- GPU TEE executes the AI model inside an attested enclave.
The Hardware Timeline:
2022: NVIDIA introduces the H100 (Hopper), the first production-grade GPU with confidential computing support via CC mode and an on-die Root of Trust.
2024: The H200 (still part of the Hopper family) builds on this with improved memory bandwidth and CC-mode performance, while AMD debuts the Instinct MI300 with Infinity Guard and SNP for secure GPU isolation.
2025 (Ongoing): Intel rolls out TDX Connect, introduced alongside the first TEE GPUs, in collaboration with NVIDIA and Microsoft, enabling secure CPU-GPU communication for confidential workloads running on CVMs.
Comparison:

How does GPU TEE work?
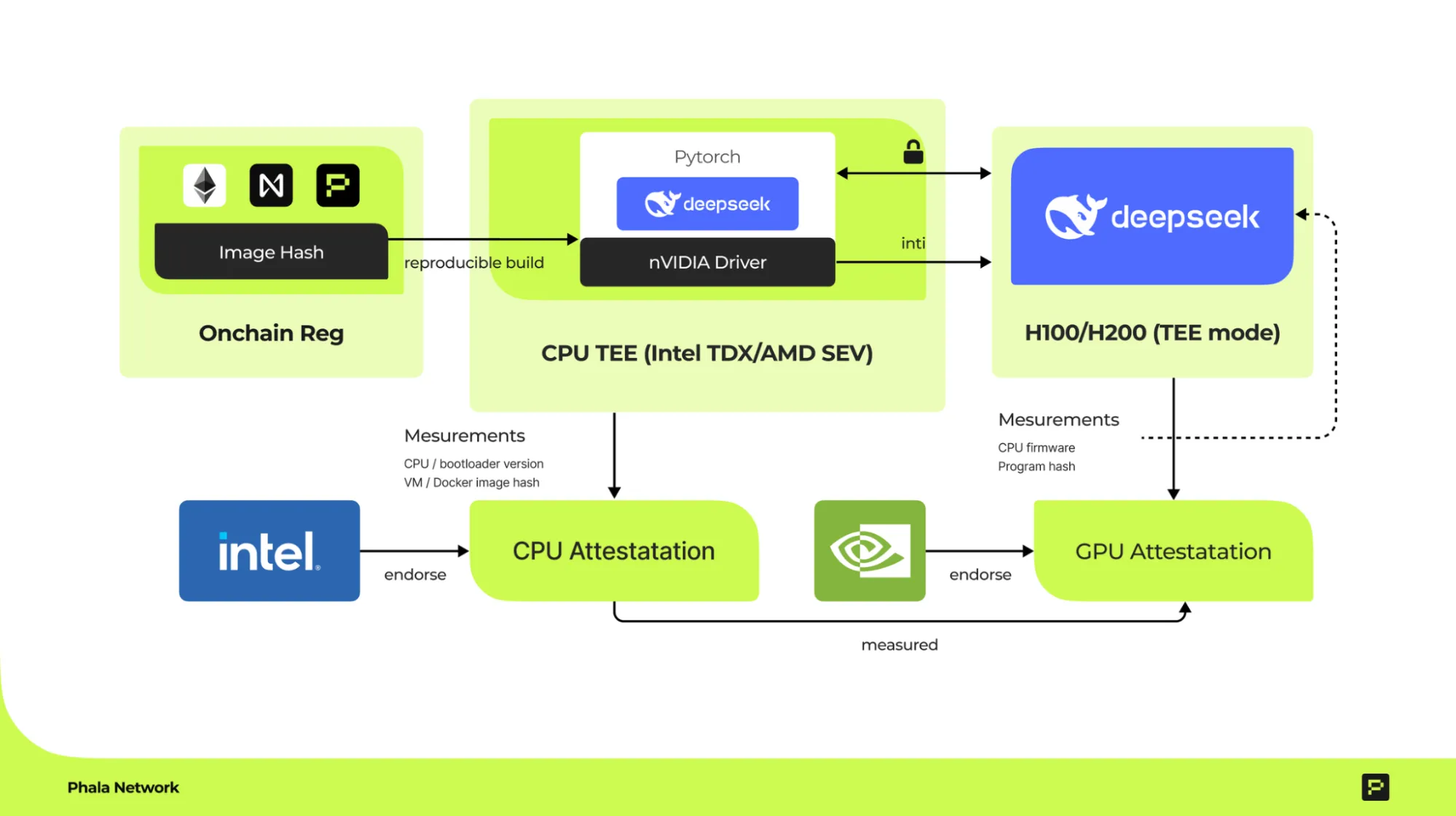
To protect an AI workload like LLM inference, a GPU TEE wraps the entire execution lifecycle from boot to shutdown in hardware-enforced security. Below is a step-by-step breakdown of the confidential computing flow, based on the architecture of modern GPUs like NVIDIA’s H100, which introduced production-grade GPU TEEs.
1. Hardware Root of Trust (RoT)
Every H100 GPU comes with a unique cryptographic identity burned into the chip at manufacture. This hardware Root of Trust ensures the GPU is genuine and provides the foundation for verifying firmware and system integrity.
2. Secure Boot
When the GPU powers on, it verifies its firmware against NVIDIA’s digital signature. If the firmware is authentic, it is loaded and then locked to prevent any tampering during runtime.
3. Confidential VM (CVM) Launch
Before using the GPU, the CPU launches a Confidential Virtual Machine using Intel TDX or AMD SEV-SNP. This isolates system memory and creates a secure base of execution, ensuring that nothing outside the TEE can access the workload.
4. GPU Enters Confidential Mode (CC-On)
The H100 GPU is assigned to the CVM and enters Confidential Computing mode. It scrubs internal state, disables performance counters, and activates hardware firewalls to block side-channel and debug access.
5. Secure Session Establishment
The GPU and CPU exchange cryptographic keys (via SPDM) to establish an encrypted channel. The GPU then generates an attestation report, signed with its hardware identity, detailing its firmware state and configuration.
6. GPU Attestation Verification
The CVM verifies the GPU’s attestation report to ensure the GPU is authentic and properly configured. This can be done either locally or through NVIDIA’s Remote Attestation Service (NRAS), which checks the signature and revocation status.
7. Encrypted Data Exchange
Because the GPU cannot access CVM memory directly, data is transferred via encrypted bounce buffers in shared memory. AES-GCM encryption with rotating IVs protects these transfers from interception or tampering.
8. Secure AI Execution
With trust established, AI models and workloads (like LLM inference) run inside the GPU TEE. The model remains private, the data is protected end-to-end, and the entire execution can be cryptographically verified, ideal for running sensitive AI in public cloud or shared environments.
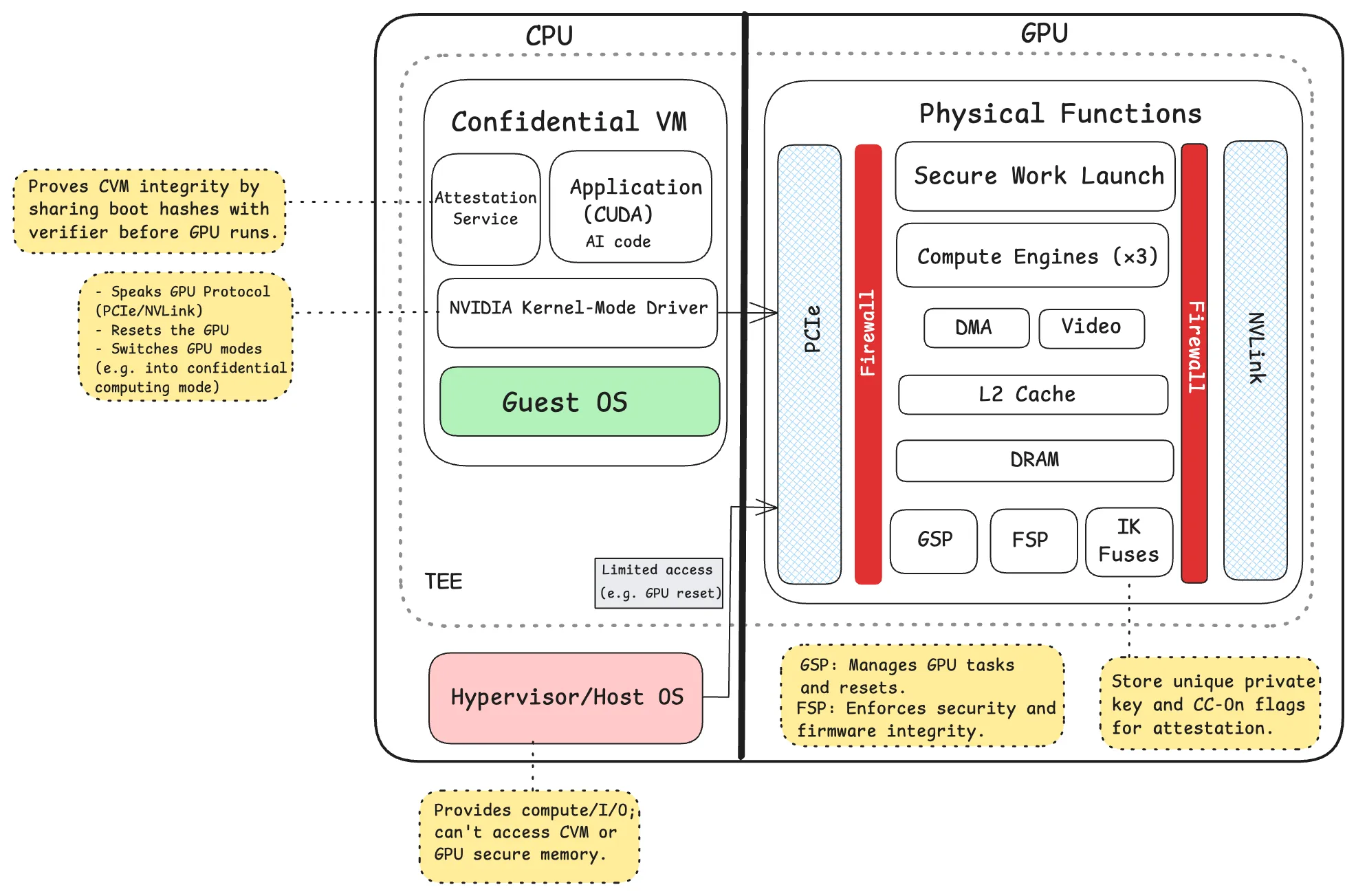
Bringing GPU TEEs Onchain
Phala builds infrastructure that lets developers run AI workloads inside hardware TEEs on both CPUs and GPUs, and verifies those workloads onchain. The aim is to make confidential computing as easy and auditable as deploying a web app.
How GPU TEEs Secure High-Performance AI?
NVIDIA H100/H200 GPUs combine parallelism with hardware-level security, turning them into ideal engines for private, verifiable inference. End-to-end protection works as follows:
- Isolation & Encryption: A hardware enclave called the Compute Protected Region (CPR) keeps code and data away from the OS or hypervisor. All traffic is AES-encrypted and decrypted only inside the enclave.
- Secure Boot & Runtime Integrity: Firmware is signed and verified at power-up; runtime checks block any tampering.
- Remote Attestation: Each GPU produces a signed report that proves its identity and configuration; clients can verify it through NVIDIA NRAS.
- On-Chain Trust (Phala): Phala anchors TEE identities and keys on-chain, enabling vendor-agnostic, decentralized verification.
- Layered Security: CPU TEEs (Intel TDX or AMD SEV-SNP) launch a Confidential VM that exchanges encrypted data with the GPU enclave, creating a full CPU-to-GPU trust chain.
Supported Hardware
Phala’s stack already runs on modern hardware TEEs end to end. On the GPU side it supports NVIDIA’s H100 and H200 cards, which ship with on-die enclaves, encrypted memory buffers, and remote-attestation flow.
On the CPU side it works inside Confidential VMs secured by Intel TDX or AMD SEV-SNP, giving the host OS no visibility into guest memory. Phala also stays tightly aligned with the TEE roadmap by partnering with NVIDIA and other vendors, ensuring new confidential-computing features land in its platform as soon as they reach production silicon.
Phala Network GPU TEE Stack
Phala Network’s GPU TEE infrastructure is built around two core components: Redpill and the private-ml-sdk. Together, they offer a complete solution for running AI workloads like LLM inference in a verifiable, secure, and isolated hardware environment.
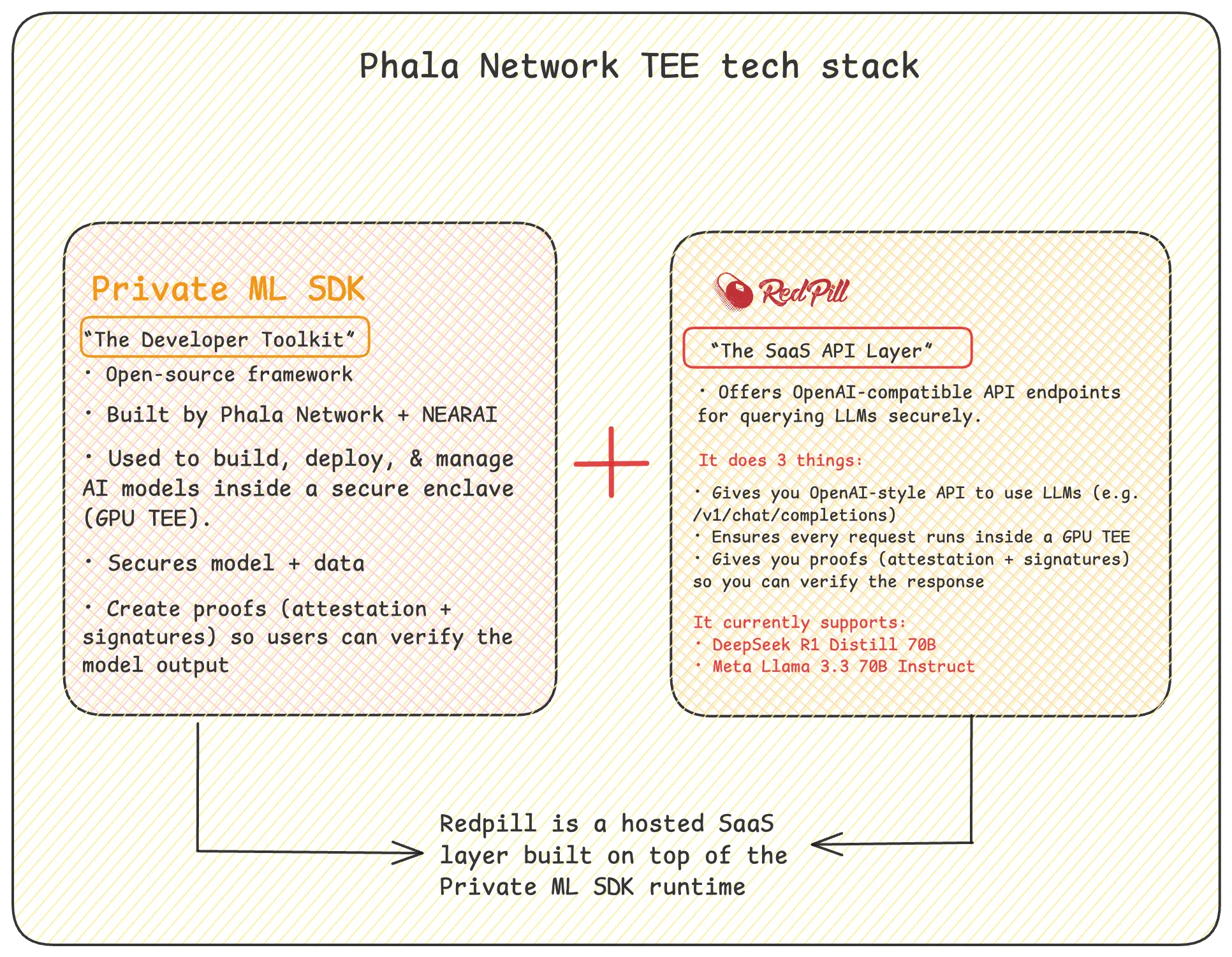
Private ML SDK:
It is a low-level open-source developer toolkit built by Phala Network (with support from NEAR AI) that allows you to run large language models (LLMs) like DeepSeek R1 inside a Trusted Execution Environment (TEE), specifically, in a combination of Intel TDX-enabled confidential VMs and NVIDIA H100/H200 GPU enclaves.
It provides everything you need to:
- Build and launch secure TDX-based guest images
- Deploy your model in a GPU TEE with encrypted memory and attestation
- Maintain fully reproducible, auditable, and isolated execution environments
- Verify model integrity using remote attestation
In short, private-ml-sdk lets developers self-host secure AI inference, giving fine-grained control over hardware, deployment, and trust guarantees, all while maintaining near-native performance.
How does it work?
You package your model and its dependencies into a Docker image, and the SDK takes care of the rest: spinning up a Confidential VM on an Intel TDX or AMD SEV-SNP host, switching an NVIDIA H100/H200 GPU into TEE mode, and loading the model into the GPU’s encrypted memory. Throughout this process it produces remote-attestation reports, so anyone can verify that the code and data are running on genuine, untampered hardware.
Once the enclave is live, user inputs stay encrypted end-to-end, inference runs at near-native speed, and the output is returned with a digital signature linked to the attestation reports. In short, Private ML SDK turns an ordinary Docker workflow into a fully verifiable, privacy-preserving AI deployment, no extra infrastructure expertise required.
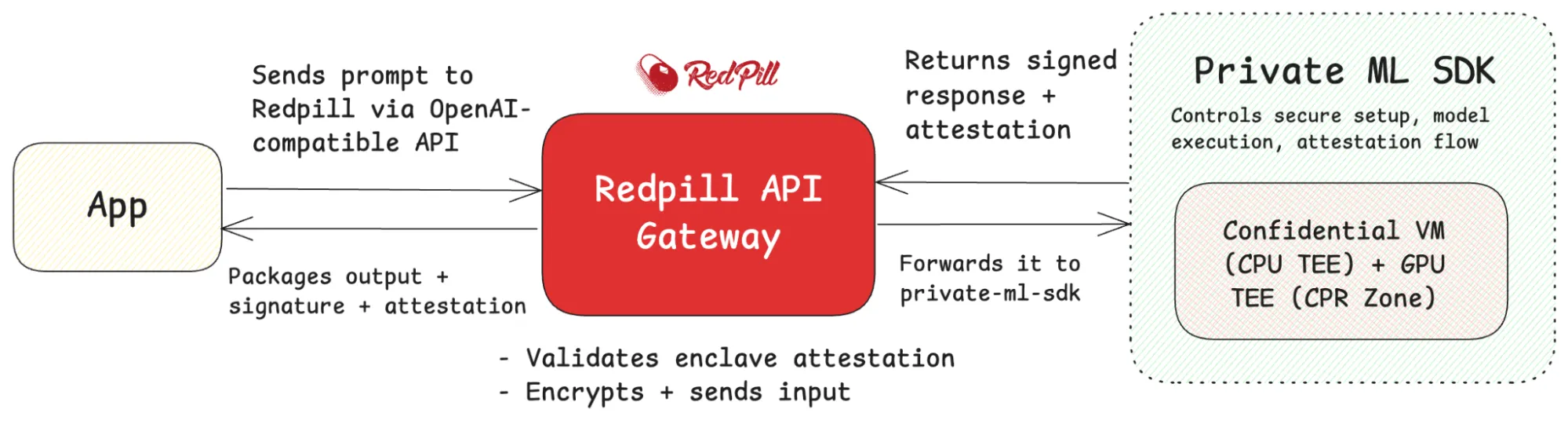
Redpill
It is a production-ready, open-source gateway from Phala Network that lets you consume LLMs already running in Intel-TDX CVMs and NVIDIA H100/H200 GPU TEEs, no hardware or Docker builds required.
It provides everything you need to:
- Call private models such as DeepSeek R1 or Llama 3 through an OpenAI-compatible /chat/completions endpoint
- Get each response signed and bundled with CPU + GPU attestation reports and the on-chain model hash
- Verify outputs with public tools (Redpill API, Etherscan) or smart contracts
- Manage API keys, usage, and billing from a single Phala Cloud dashboard
How does it work? You POST a standard JSON prompt; Redpill checks live attestation on the target TEE, pipes the encrypted input into the enclave, streams the answer back, and signs it with a key generated inside the TEE. The reply arrives with the data, signature, and verification URLs, turning a simple API call into a fully auditable, privacy-preserving inference.
Benchmark Highlights
Phala Network ran the world’s first GPU TEE benchmark on open-source LLMs. It turned out that the overhead of running inference inside a secure enclave is low and manageable.
Using NVIDIA’s H100 and H200 GPUs, the study evaluated models such as Llama 8B, Phi-3 14B, and Llama 70B, comparing performance with confidential computing (TEE) mode enabled and disabled.
Key findings:
- Less than 9% average performance loss, with no code modifications required
- Larger models (e.g., Llama 70B) showed near-zero overhead
- Startup time (time-to-first-token) increased by ~20–25% due to attestation and encryption
- Throughput and latency during inference were almost unchanged
- Primary bottleneck was PCIe data transfer, not GPU-side computation
The benchmark confirms that secure, large-scale AI inference using GPU TEEs is now practical, without disrupting existing workflows or compromising speed.
GPU TEE Real-Life Use Cases
AI & ML Applications
- Healthcare AI: Run diagnostics or genomics models on shared H100 clusters while keeping patient data encrypted and compliant through attestation.
- Federated Learning: Train models across siloed datasets (e.g., hospitals) without exposing raw data.
- Secure Inference: Handle real-time encrypted inputs (e.g., chatbots) with verified, private model execution.
Web3 & Blockchain
- Onchain Verifiable AI: Smart contracts validate attested model outputs to prevent spoofed responses.
- Decentralized Agents: AI bots (e.g., in trading) run securely using GPU TEEs, ensuring strategy privacy.
- ZK Acceleration: zkVMs offload circuit execution to attested GPUs, reducing proving time while ensuring integrity.
In Practice
- Ai16z: Uses Phala Cloud to host private AI models with full attestation.
- Flashbots X: Pilots private transaction processing using GPU TEEs for scalable DeFi execution.
Future Outlook for GPU TEEs
Phala’s next phase turns confidential GPU power into a true Web3 service. In the coming year, enclave-based AI apps will be versioned and upgraded through on-chain governance, so the community, not a single vendor, decides when code ships or rolls back. At the same time, a pay-as-you-go marketplace will open Hopper-class GPU TEEs by the hour, letting solo builders tap secure compute without owning any hardware and settling usage and attestation proofs directly on-chain.
Looking ahead to 2025, that rental fabric will stretch beyond NVIDIA. The same attestation flow is being ported to AMD’s Infinity Guard–equipped MI300 GPUs and Intel accelerators protected by TDX, paving the way for workloads to roam freely to whatever silicon offers the best price or latency. The destination is a hardware-agnostic, elastically priced layer where confidential AI can scale as easily as any other blockchain service, secure by default, portable by design.
Conclusion
GPU TEEs close the last gap in AI security by keeping data and models private even while they run. Phala Network makes those enclaves usable via open-source tools and on-chain attestation, so developers can deploy fast, verifiable AI without trusting the host cloud. Secure, decentralized AI is now a practical reality.