
Introduction
Large Language Models (LLMs) are increasingly deployed in cloud and multi-tenant environments where data privacy and model confidentiality are paramount. Traditional protections like encrypting data at rest or in transit are insufficient once data is being processed (i.e. “in use”) (Confidential Computing on NVIDIA H100 GPUs for Secure and Trustworthy AI | NVIDIA Technical Blog). Both user inputs (which may contain sensitive personal or enterprise data) and the model itself (often valuable intellectual property) must be protected during inference.
Trusted Execution Environments (TEEs) address this by creating isolated, hardware-protected enclaves for computation, preventing even privileged system operators from accessing the code or data inside (Confidential Computing on nVIDIA H100 GPU: A Performance Benchmark Study). While CPU-based TEEs (e.g. Intel SGX) have existed for some time, their limited memory and performance posed challenges for large-scale ML workloads.
Today, GPU TEEs – enabled by NVIDIA’s Confidential Computing technology in modern data-center GPUs – allow us to run LLM inference in secure enclaves with minimal performance overhead. This report explores the technical architecture of GPU TEEs for LLMs, how NVIDIA H100 Confidential Computing works for secure ML inference, and dives deep into real-world implementations (Phala Network’s “Absolute Zero” case with DeepSeek R1, NearAI’s Private ML SDK, and RedPill’s Confidential AI Inference framework). We also provide example code for deploying LLMs in GPU TEE environments, and discuss the benefits, limitations, and threat models addressed by this approach.
GPU TEE Architecture for LLM Inference
GPU Trusted Execution Environments extend the enclave concept to GPUs, combining a secure CPU environment with a secure GPU context. In a typical setup, a confidential VM or enclave runs on the CPU (using technologies like Intel TDX or AMD SEV-SNP), and an attached NVIDIA GPU (such as H100) operates in “Confidential Computing” mode. This hybrid design allows an LLM to utilize the GPU’s acceleration within a protected envelope that encompasses both CPU and GPU memory.
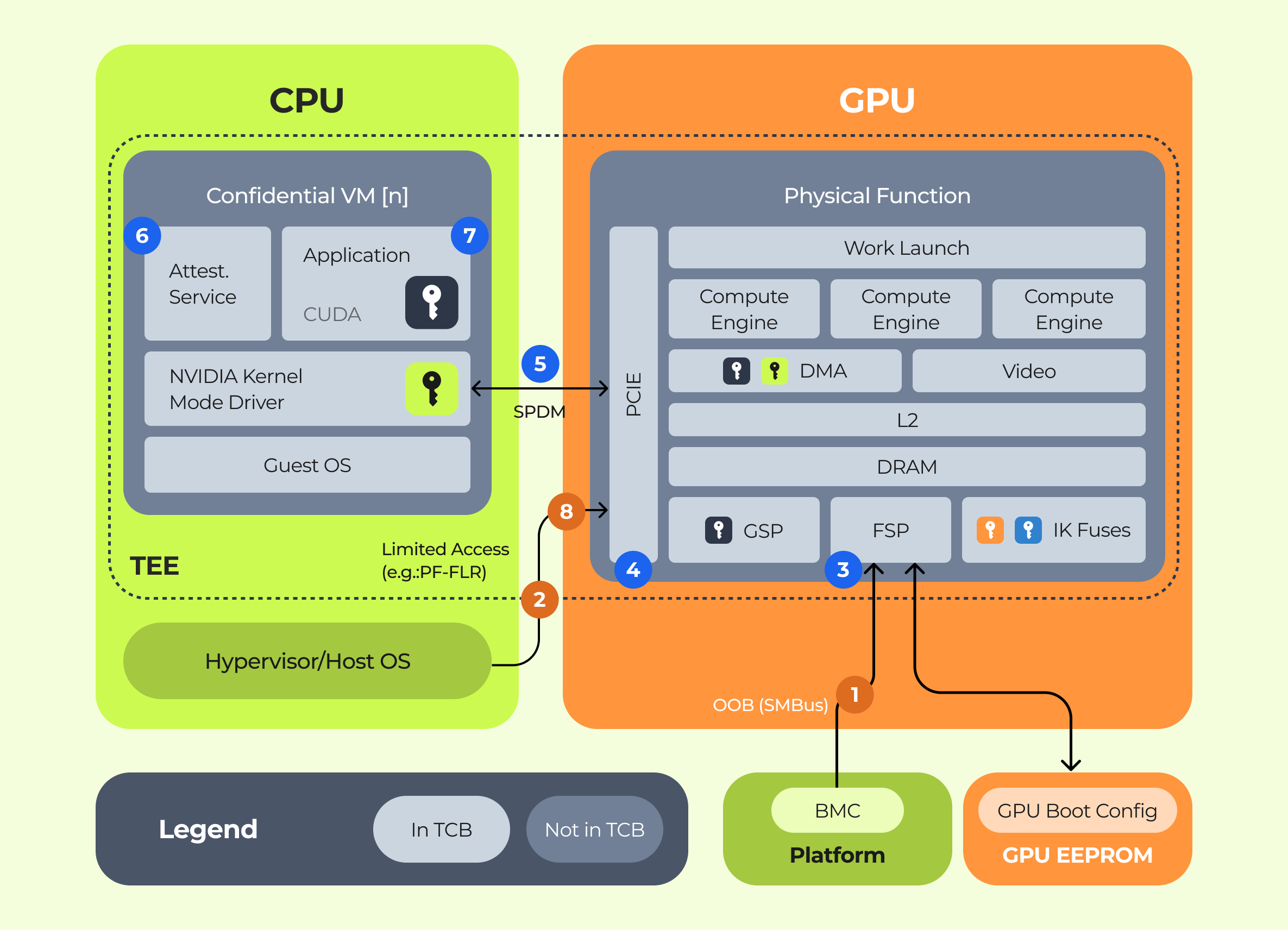
Chain of Trust: When the GPU is booted in Confidential Computing mode (often called “CC On”), it establishes a hardware-based root of trust on the GPU itself . The GPU undergoes a secure, measured boot sequence so that its firmware and microcode are verified. Next, a secure communication channel is established between the GPU and the CPU’s TEE using the Security Protocol and Data Model (SPDM) protocol . This ensures the GPU driver (running in the CPU enclave) and the GPU hardware mutually authenticate each other. The GPU then generates an attestation report – a cryptographically signed set of measurements (e.g. firmware version, secure boot status, and loaded GPU program hash) . Similarly, the CPU TEE (the confidential VM) produces its own attestation (covering the bootloader, OS, and loaded application code or container image). Together, these attestation artifacts allow a remote client to verify that the exact expected software (OS, LLM model, etc.) is running on genuine TEE hardware (Intel CPU and NVIDIA GPU), and that no tampering has occurred. Only if the attestation is valid (matching known good measurements) will a client proceed to trust the enclave .
Isolated Execution and Memory Encryption: In GPU TEE mode, the NVIDIA H100 enforces that all data exchanged with the CPU is encrypted in transit, and that the GPU’s memory is isolated from other contexts (Confidential Computing on nVIDIA H100 GPU: A Performance Benchmark Study). In practice, this is achieved with encrypted “bounce buffers” for PCIe data transfers – data leaving the CPU’s encrypted memory is encrypted over the bus and only decrypted within the GPU’s secure memory. The GPU’s on-board memory is safeguarded so that even a hostile host can’t dump its contents. Meanwhile, the CPU TEE ensures that any data in system RAM (model weights, intermediate buffers) remains encrypted to the outside world. Thus, end-to-end confidentiality is maintained: data and model weights stay protected both in the CPU memory and the GPU memory, as well as in transit between them. Importantly, this is all done in hardware, transparent to the application – from the perspective of the ML code (e.g. PyTorch), it’s just performing normal GPU inference, but under the hood the GPU and CPU are enforcing encryption and isolation.
Minimal Performance Overhead: A concern with any TEE is the performance cost of isolation and encryption. Fortunately, GPU TEEs impose very little slowdown for LLM inference. Studies have shown that when running large models on H100 in TEE mode, the computational overhead inside the GPU is negligible – the main cost is a slight increase in CPU-GPU I/O latency due to encryption of data transfers. For most typical LLM prompt sizes, the end-to-end throughput hit is under 7%. This means we can get nearly native performance (often >99% of normal speed) even while using full confidentiality. In contrast, earlier CPU-only TEEs often struggled with performance (for instance, Intel SGX had severe memory paging issues with large models). By leveraging the GPU’s hardware accelerators with only minor encrypted I/O overhead, GPU TEEs enable practical secure inference on large models that would be impractical to run in a CPU enclave alone.
NVIDIA H100 Confidential Computing Technology
NVIDIA’s Hopper architecture (H100) is the first GPU to support Confidential Computing capabilities, making GPU TEEs possible . When the H100 GPU is operated in confidential mode, it provides a hardware-enforced TEE that preserves both confidentiality and integrity for code and data on the GPU (AI Security with Confidential Computing | NVIDIA). Data-in-use Protection: In this mode, any data or model parameters moved into the GPU for processing are kept hidden from the rest of the system – even the hypervisor or host OS cannot snoop on GPU memory or registers . The H100 achieves this with a combination of features: memory encryption, secure boot, and attestation. All GPU firmware is authenticated (signed by NVIDIA) at boot time, so no malicious firmware can run . The H100’s driver and control interface expect to run within a CPU-side TEE, as part of the secure chain of trust (for example, a Linux guest running under Intel TDX). Through the SPDM secure channel, the GPU receives confirmation it’s talking to a trusted, attested CPU enclave.
At that point, the GPU’s on-die root-of-trust generates an attestation quote that can be verified by remote parties using NVIDIA’s attestation service. This attestation report includes measurements of the GPU’s state (such as cryptographic hashes of the loaded model code or CUDA kernel binaries, and the GPU’s firmware version). A client can submit this quote to NVIDIA’s public attestation service to confirm it’s genuine and up-to-date (ensuring, for example, that the GPU isn’t using a revoked firmware) (Get Started | RedPill).
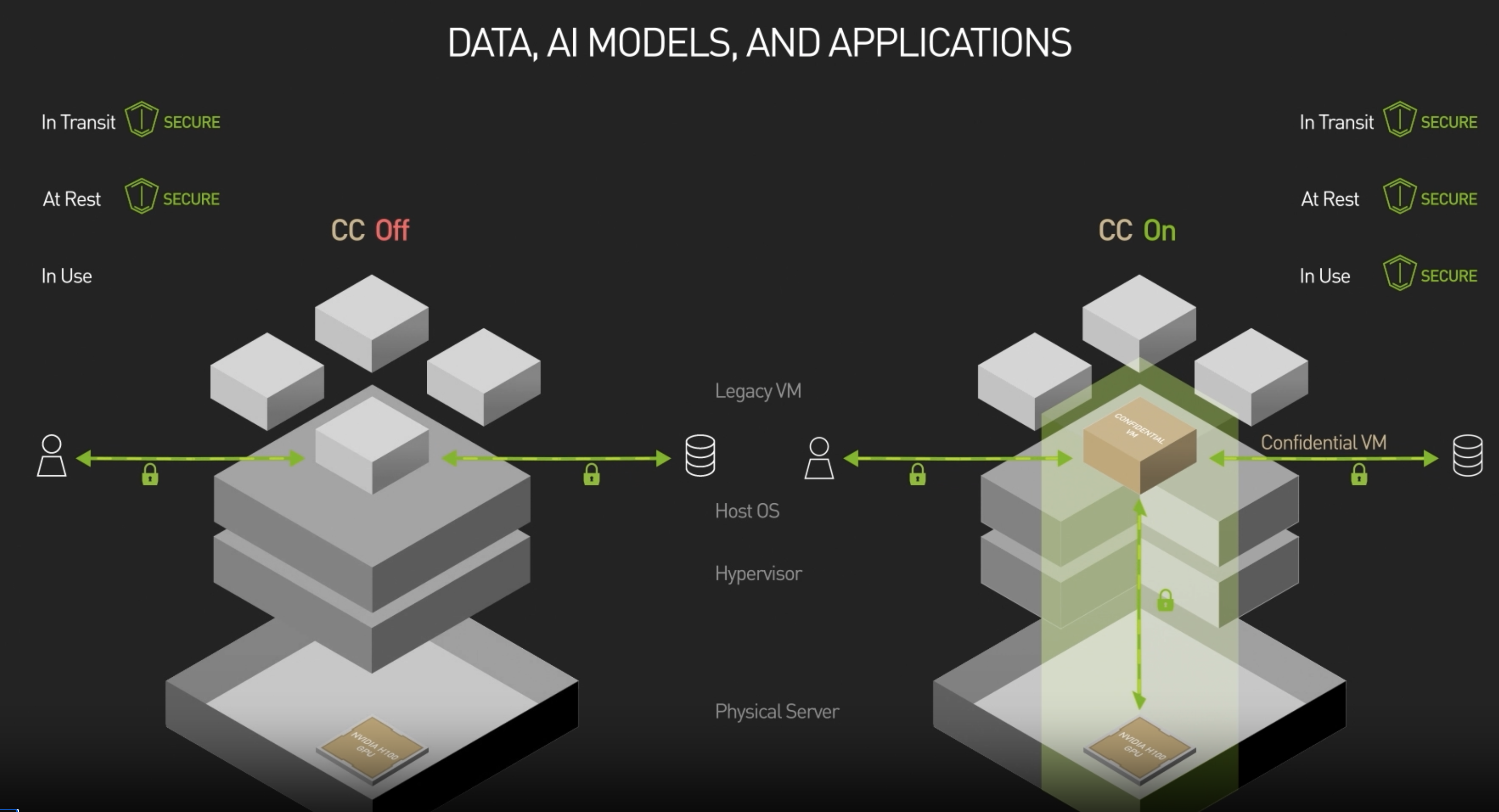
Crucially, NVIDIA’s Confidential Computing requires a complementary CPU TEE. In practice, enabling H100 confidential mode is done in a VM that is itself running in a TEE (like an AMD SEV-SNP or Intel TDX VM). This is reflected in cloud offerings (e.g. Azure’s confidential GPU VMs pair AMD Milan CPUs with SEV-SNP and H100 GPUs). The CPU TEE provides the protected execution environment for the OS and NVIDIA’s driver, while the GPU TEE protects the heavy-duty ML computations. The overall security is only as strong as both of these components – the GPU can ensure its own processes are secure and attest its state, but it must rely on the CPU enclave to defend the communication path and to attest the rest of the software stack. When configured correctly, this two-layer TEE (CPU + GPU) means the entire LLM inference pipeline – from receiving an encrypted prompt, to running the model, to producing a result – can be confined within a hardware-enforced trust boundary. NVIDIA’s design goal was to make this as seamless as possible: in fact, no code changes are required to run AI workloads in the GPU TEE. An existing PyTorch or CUDA application can run on a confidential H100 just as it would normally; the only difference is how the VM is launched and how attestation is handled. This makes adoption easier – models can be moved into protected enclaves “with a few keystrokes” by enabling the confidential VM and GPU mode.
From a performance standpoint, NVIDIA reports that accelerated computing tasks run with essentially the same speed in the confidential mode once the environment is set up. Initial research confirms that the GPU’s computation is unaffected, and the overall throughput penalty is mostly due to encrypted I/O, as discussed earlier. In summary, the H100 (and its successors like the upcoming Blackwell/H200 GPUs) provide the foundation for secure ML inference by combining high-performance GPU acceleration with TEE security. This foundation is now being leveraged by various frameworks and platforms to deploy privacy-preserving LLM services.
Case Study: Phala Network’s LLM Inference with DeepSeek R1 in a GPU TEE
Phala Network, a decentralized cloud computation platform, has been pioneering the use of GPU TEEs to secure AI models. In response to concerns over the privacy of AI models developed overseas (specifically a Chinese LLM called DeepSeek R1), Phala promoted a “Don’t trust, verify” approach dubbed “Absolute Zero” – meaning zero trust in the model’s origin, and instead complete verification by running it in a trusted environment (Absolute 0 CCP: Use DeepSeek R1 with GPU TEE for Verified AI Security). The idea is that even if you don’t trust the model provider, you can run their model inside a TEE that guarantees the model can’t “phone home” or leak your data, and you can independently verify that the model runtime is secure. To achieve this, Phala combined its on-chain TEE platform with GPU confidential computing.
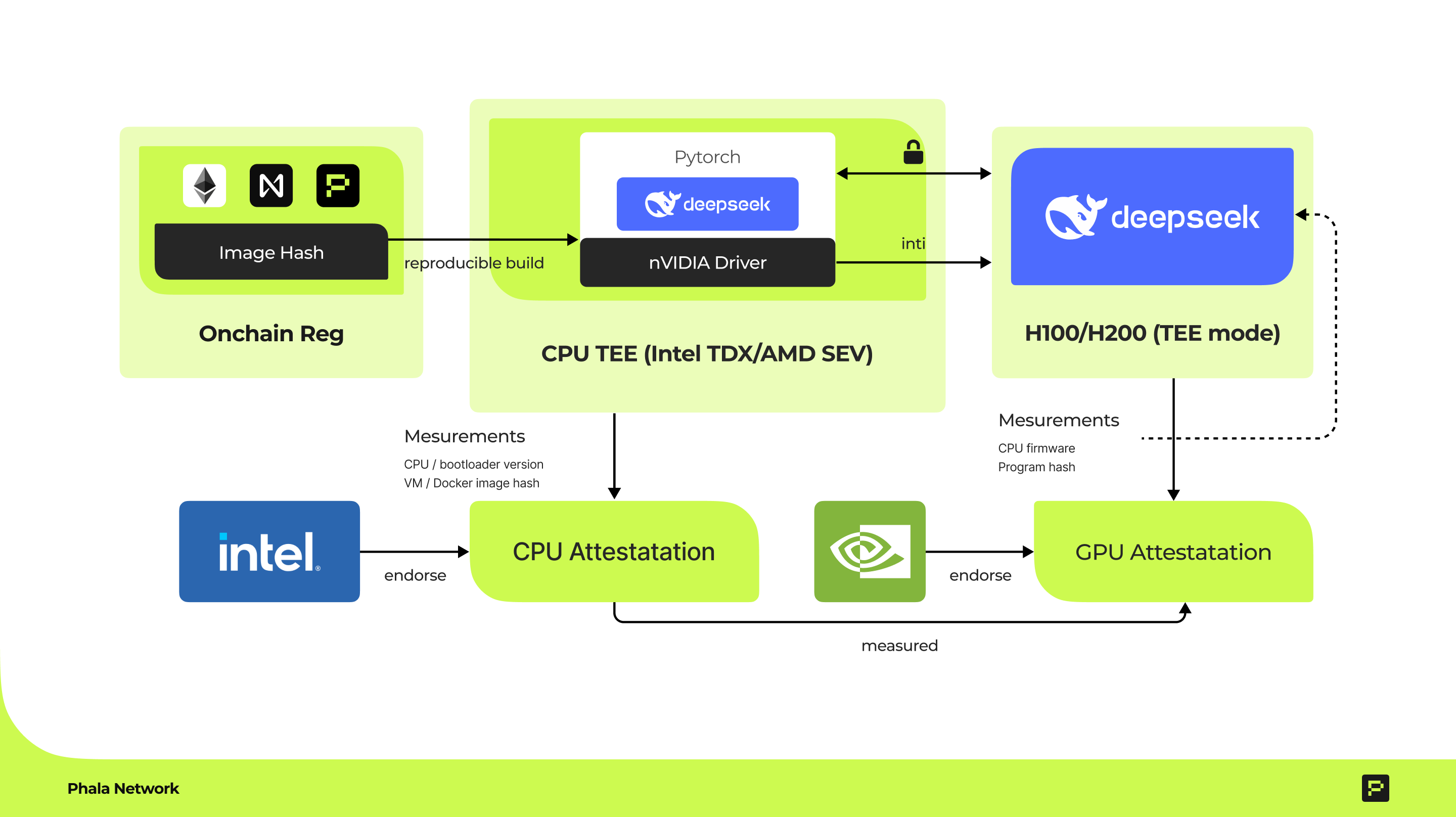
Phala’s TEE Tech Stack: The core components are OpenRouter & RedPill and the Private ML SDK (more on these later), which together allow AI models like DeepSeek R1 to run inside a GPU TEE . With this stack, Phala or any developer can deploy an LLM such that inference occurs entirely within an isolated enclave, and remote users can obtain cryptographic proof of the enclave’s integrity. In February 2025, Phala demonstrated this by hosting the DeepSeek R1 model (a 70-billion parameter LLM) in a GPU TEE and allowing users to query it with full data confidentiality. The Absolute Zero case study highlighted the following workflow for secure LLM deployment :
- Secure Model Hosting: Using the Private-ML-SDK, the DeepSeek R1 model is loaded inside a TEE-enabled server. This involves setting up the hardware (NVIDIA H100 GPUs in TEE mode, with a TDX-enabled CPU), compiling or containerizing the model server with the SDK, and launching it such that it attests its state. Phala’s system ensures the model weights themselves are only decrypted inside the enclave, protecting the model owner’s IP.
- Remote Attestation: Once running, the service produces attestation evidence (from both the CPU enclave and GPU) which can be checked by clients. This lets anyone verify that the DeepSeek R1 instance is indeed running inside a genuine TEE and that no one has tampered with it. In Phala’s design, even the Phala network operators do not have access to the model internals – they only see encrypted data – so users do not have to trust Phala, they can trust the hardware guarantees.
- Inference with Privacy: Users can then send prompts to the model through a secure channel. The data is encrypted on the client side, remains encrypted all the way into the enclave, and is only decrypted inside the TEE for processing. The model generates a response, which is encrypted and sent back to the user. Thus, at no point can any outside observer read the input or output text. This addresses concerns like those raised in the media about AI services mishandling private data – even if the model is hosted in the cloud, the cloud provider cannot see your prompt or the model’s answer.
- Verification of Results: Because the entire execution is in a TEE, the results can be accompanied by a proof (signature or attestation) that they indeed came from the genuine DeepSeek model running in the enclave. Phala’s approach allows a user to verify that the response wasn’t generated by a fake or altered model. This is especially important here because one might worry that a malicious host could swap out the model or inject a spying routine. With attestation, the user can catch that – the cryptographic measurements would differ if, say, the model binary was modified.
In essence, Phala’s Absolute Zero demo with DeepSeek R1 proved that GPU TEEs enable a trustless deployment of large models. It turned the controversial DeepSeek cloud model into a verifiable secure service: users could query the model without fear of data leakage, and they didn’t even need to trust the model provider’s privacy claims – they could verify the environment themselves. This showcases the power of GPU TEEs for privacy-preserving ML: even untrusted models or untrusted infrastructure can be leveraged safely as long as they run inside a properly attested enclave.
Private ML SDK – Toolkit for Confidential LLM Deployment
To make deploying LLMs in GPU TEEs more accessible, NearAI and Phala co-developed an open-source toolkit called the Private ML SDK. This SDK provides all the building blocks to run large models in a secure enclave that spans CPU and GPU. At a high level, the Private ML SDK sets up a Confidential AI Inference environment (as illustrated earlier) which includes: a CPU TEE VM, secure gRPC/HTTP interfaces, attestation flows, and integration with frameworks like PyTorch for running the model on the GPU.
According to its documentation, “Private ML SDK provides a secure and verifiable solution for running LLMs in TEEs, leveraging NVIDIA’s TEE GPU technology (H100/H200/B100) and Intel TDX support”. In practice, this means a developer can use the SDK to package their model and serving code (for example, a Flask app or a LangChain agent) into a confidential VM image. The SDK handles the low-level details like enabling the GPU’s TEE mode and establishing attestation. Some key features of the Private ML SDK include (GitHub - nearai/private-ml-sdk: Run LLMs and agents on TEEs leveraging NVIDIA GPU TEE and Intel TDX technologies.):
- Tamper-proof execution: The runtime ensures that both model and data are handled entirely within the enclave, preventing any external tampering or observation. Even kernel-level malware on the host cannot interfere with the model’s execution or extract secrets.
- Secure communications: All communication between the client and the model (and between the CPU and GPU internally) is end-to-end encrypted. This prevents man-in-the-middle attacks or eavesdropping on data in transit.
- Remote Attestation & Verifiability: The SDK exposes mechanisms to generate and retrieve attestation quotes from Intel and NVIDIA, so that a client (or an auditor) can verify the enclave’s identity and the integrity of the software stack. It also supports signing the inference results (as we’ll see with RedPill) to prove they came from a trusted environment.
- Reproducible Builds: To complement attestation, the SDK encourages reproducible container or VM images. By registering a hash of the expected image (for instance, on a blockchain or registry service), one can compare it with the attested measurement at runtime to be sure the exact intended model code is running. This ensures code integrity – that no malicious code has been inserted.
- Performance Optimization: The SDK is optimized to utilize GPU acceleration fully, achieving near-native speed for inference. It includes support for models running under popular frameworks (like using Nvidia’s cuBLAS, TensorRT, etc., inside the enclave) so that developers don’t sacrifice performance for security.
Under the hood, the Private ML SDK orchestrates the launch of a TDX-enabled VM (or AMD SEV VM) which loads an image containing the ML model server. This image typically includes the NVIDIA driver and CUDA libraries, the ML framework (PyTorch, etc.), and the model files. The VM boots on a host that has an H100 GPU attached, and the SDK triggers the GPU’s CC mode initialization (often via a special driver or hypervisor call). Once up, the CPU enclave attests to an attestation service (e.g., Intel’s DCAP for TDX), and the GPU generates its attestation which can be retrieved via NVIDIA’s attestation service (Get Started | RedPill). The SDK provides APIs or scripts to gather these quotes and bundle them (as JSON) to provide to end-users or to an on-chain verification contract.
For developers, using the SDK might involve writing a config file (to specify the model to load, hardware resources, etc.) and then running a build script. For example, one would prepare a Docker image with their application, then use a command to convert it into a confidential VM image (with the necessary secure boot and attestation keys). The NearAI/private-ml-sdk repository contains examples of how to define an app.yaml and an env-file for the confidential deployment, which include the service definitions and any secrets that should be injected into the enclave at runtime. The end result is that, instead of deploying an LLM service to a regular VM or container, you deploy it to a Confidential VM using the Private ML SDK. From that point on, clients can interact with it just like any other API, but with the added ability to request attestation evidence and have guarantees of privacy.
In summary, NearAI’s Private ML SDK is a powerful tool that abstracts away much of the complexity of setting up a GPU TEE. It enables a workflow where model providers can easily host their models in a way that clients can trust without revealing the model weights or user inputs. This toolkit underpins many of the real-world implementations of confidential AI inference, including the Phala Network use-case above and the RedPill service described next.
Confidential AI Inference Service: OpenRouter
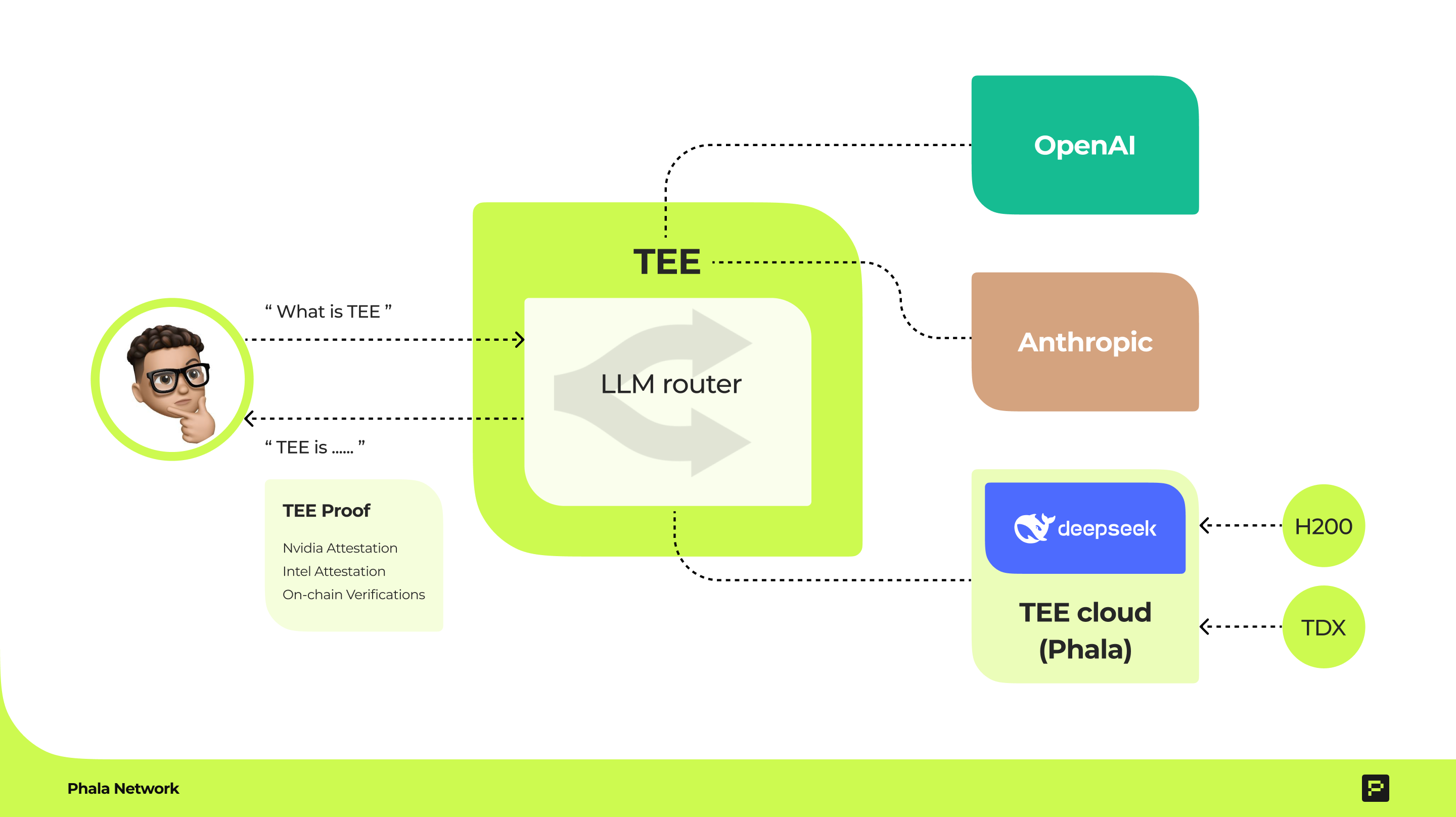
OpenRouter is an open-source project that acts as a universal API gateway for accessing and integrating large language models (LLMs) from a wide variety of providers. By unifying different model APIs under a single, OpenAI-compatible interface, OpenRouter simplifies development and experimentation for builders working across the AI landscape. Developers can route requests to popular models like OpenAI's GPT, Anthropic's Claude, Meta's Llama, Mistral, and others—often including open-source models—without having to individually manage keys, rate limits, or differing APIs. It also supports custom routing logic, load balancing, and fallback strategies, making it a powerful tool for researchers, startups, and enterprises aiming to leverage multiple LLMs efficiently in production or prototyping.
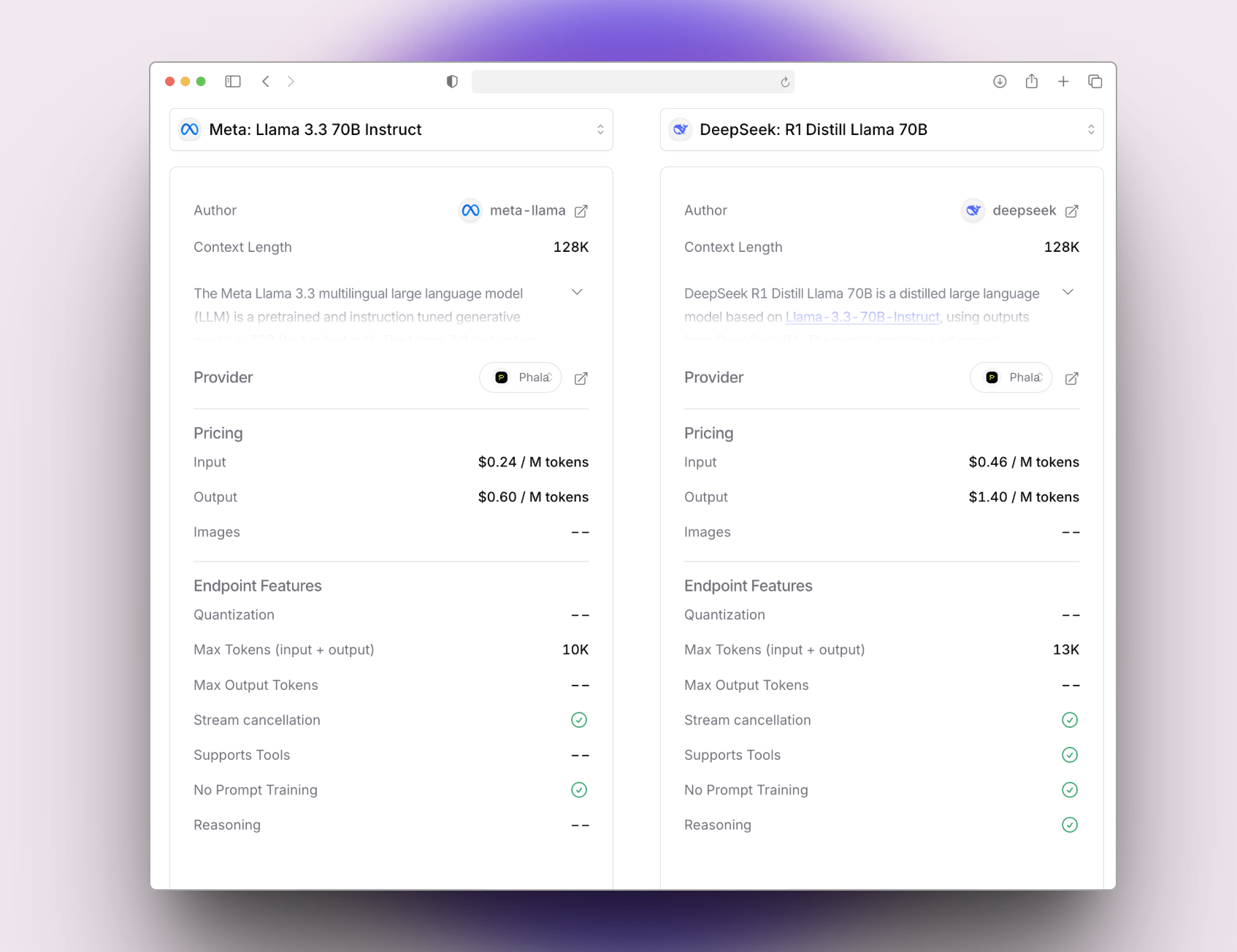
https://openrouter.ai/deepseek/deepseek-r1-distill-llama-70b | https://openrouter.ai/meta-llama/llama-3.3-70b-instruct
Attestation and Key Establishment: When a LLM server instance starts up (for a given model), it performs a series of steps to establish trust:
- Enclave Key Generation: The service generates a fresh signing key pair inside the TEE upon launch . The private part of this key never leaves the enclave. It will be used to sign inference results. The public part will be made available to clients for verification.
- TEE Attestation: The service obtains both an Intel TDX quote (for the CPU VM) and an NVIDIA attestation (for the GPU) and packages these into an attestation report JSON. Importantly, this report includes the enclave’s newly generated public key (often represented as an Ethereum-like address) bound to the TEE measurements (Get Started | RedPill). In other words, the attestation proves “This specific secure hardware instance has generated this public key”.
- Client Verification: A client can request the attestation report via OpenRouter’s API at any time (there’s an endpoint
/attestation/report?model=<model_name>) . Using this, the client first verifies the Intel quote and NVIDIA quote – e.g., by sending the NVIDIA quote to NVIDIA’s attestation service to validate it . This confirms the hardware authenticity (that it’s an H100 in CC mode and a trusted CPU). Then, the client inspects the public key in the report and trusts that any message signed by the corresponding private key indeed came from inside that enclave .
Once this trust setup is done, the user can perform inference requests. RedPill’s API is designed to be similar to OpenAI’s API, making it familiar for developers. For example, to create a chat completion, a client sends an HTTP POST to the service with a JSON payload containing the conversation and specifying the model. Below is a simplified example of using RedPill’s API to query the DeepSeek R1 (70B) model:
curl https://openrouter.ai/api/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $OPENROUTER_API_KEY" \
-d '{
"model": "deepseek/deepseek-r1-distill-llama-70b",
"messages": [
{
"role": "user",
"content": "What is the meaning of life?"
}
]
}'(Example of a chat completion request to OpenRouter confidential inference API, targeting the DeepSeek-R1 70B model. The API key and model name are specified in the request. The prompt is kept minimal here for brevity.)
Openrouter / Redpill will process this request by forwarding it to the DeepSeek model running inside the enclave. The model generates a completion (in this case, presumably identifying itself or responding). The response is sent back to the client as JSON, just like OpenAI’s API. However, RedPill includes an important extra: it computes a cryptographic signature over the response. Specifically, after the response is produced, the enclave’s signing key is used to sign a combination of the request and response hashes. The signature (and the original public key identity) can then be used by the client to verify that this output indeed came from the enclave.
To retrieve the signature (e.g Redpill), the client can call another endpoint, for example:
# Using the request ID returned in the completion response:
curl -X GET "https://api.red-pill.ai/v1/signature/<REQUEST_ID>?model=phala/deepseek-r1-70b&signing_algo=ecdsa" \
-H "Authorization: Bearer <REDPILL_API_KEY>"
This returns a JSON containing the text (which is a concatenation of the hash of the request and the hash of the response) and the signature . The client can verify this signature using the public key obtained from the attestation step. In fact, RedPill conveniently provides the public key in the form of an Ethereum address (the signing_address) which means one can even use standard tools (like ethers.js or an Ethereum signature verifier) to check that the signature is valid. The RedPill docs suggest using Etherscan’s signature verification tool as a quick way to paste the address and message to verify the signature. A valid signature proves that the response came from the trusted enclave and not from any intermediate server or attacker. If an adversary tried to fake a response or alter it, they would not have the enclave’s private key, and thus the signature check would fail.
Through this mechanism, RedPill provides verifiable AI inference. Users not only get the benefit of confidentiality (nobody can see their prompt or the model’s answer except the enclave) but also integrity assurance (the answer hasn’t been tampered with, and it indeed came from the intended model running in a TEE). This is particularly valuable for sensitive applications or for using models from third parties. For instance, a company might allow a third-party model to be used on its sensitive data only if it can obtain such proof that the model service is running in a secure enclave. RedPill essentially operationalizes the combination of NVIDIA H100’s confidential computing and Intel TDX into a consumable web service.
Benefits and Limitations of GPU TEEs vs. Traditional CPU TEEs
GPU TEEs offer several key benefits over CPU-only TEEs for deploying LLMs:
- Scalability and Performance: GPU TEEs can handle the immense computation and memory requirements of large neural networks. CPU TEEs (like Intel SGX enclaves) were often limited to a few hundred MB of protected memory (SGX EPC) and would incur large overheads when running big models, if it was even possible at all (for example, a 70B parameter model is hundreds of GB in size, far beyond SGX limits). In contrast, with GPU TEEs, models can utilize tens of GB of GPU memory, and the overhead is minimal (often <5% as noted). This bridges the gap between security and performance, enabling high-throughput, low-latency inference that was infeasible in CPU enclaves .
- End-to-End Protection for ML Workloads: A CPU TEE alone cannot protect data once it is handed off to a GPU for acceleration (since historically the GPU was outside the trust boundary). By incorporating the GPU into the TEE, we get full-stack coverage – the data remains protected even during the GPU’s matrix multiplications and tensor operations. This is critical for ML, which relies on GPUs for efficiency. Essentially, GPU TEEs extend confidential computing to the entire ML pipeline rather than stopping at the CPU.
- Familiar Programming Model: Developers do not need to rewrite their models for some specialized enclave SDK (as was often the case with early TEEs). NVIDIA’s solution allows running standard frameworks (PyTorch, TensorFlow, etc.) with no code changes – the protections are applied at the hardware/driver level. This greatly lowers the barrier to adoption. You can take an existing LLM, deploy it in a confidential VM with an H100, and get security benefits immediately, rather than redesigning the application for an enclave.
- Stronger Attacker Model: The combination of CPU and GPU TEEs means an attacker would need to break two hardware enclaves simultaneously – a much stronger protection than a single enclave. The CPU enclave protects the orchestration and data preprocessing, while the GPU enclave protects the core ML compute. Even if one were theoretically compromised, the other still ensures some level of protection (though in practice they are both needed for full security). Additionally, modern TEEs like TDX/SEV and H100 provide features (like integrity checking, anti-rollback, and formal attestation reports) that older TEEs like SGX lacked or had in weaker forms. This improves trust in the overall system.
Despite the advantages, there are some limitations/trade-offs to note:
- Hardware Availability: GPU TEEs currently require the latest hardware (NVIDIA Hopper GPUs or newer). These are expensive and not yet ubiquitous. In contrast, simpler CPU TEEs have been around on commodity CPUs for a while. Organizations without access to H100/H800 or upcoming H200 GPUs cannot leverage GPU TEEs until they upgrade or use a cloud that offers them.
- Complex Setup: Standing up a GPU TEE involves coordinating two sets of attestation (CPU and GPU) and ensuring the hypervisor, OS, and drivers all support confidential compute. Frameworks like the Private ML SDK and platforms like RedPill are helping to automate this, but it’s still a non-trivial deployment compared to standard GPU hosting. The operational complexity (key management, attestation verification, etc.) is higher, although projects like Phala are abstracting a lot of that complexity for end-users.
- Dependency on Vendors: Relying on Intel and NVIDIA for the root-of-trust means one must implicitly trust these vendors’ security measures. For truly sensitive cases, some might consider it a risk that a backdoor or vulnerability in the hardware could undermine the TEE (for example, an exploit in the GPU firmware). That said, this is a general concern with TEEs, not specific to GPU TEEs, and both Intel and NVIDIA have undergone audits for their implementations.
- Compatibility and Feature Parity: Not all features available in a normal environment are yet supported in a confidential VM with GPU. For instance, certain low-level profiling or debugging tools might be unavailable, and multi-GPU sharing across VMs might be limited. Also, the current generation focuses on inference use-cases; training in GPU TEEs (with multiple GPUs, high inter-node communication) is an area still being explored and may have additional overhead.
- CPU TEE Limitations Persist: A GPU TEE does not eliminate the need for a CPU TEE, which means the system inherits some limitations of those. For example, the secure boot of the VM, the size of the TEE VM, and possible performance overhead on the CPU side (crypto operations, etc.) are still factors. We mitigate the CPU being the bottleneck by offloading to GPU, but if the CPU side code (e.g. data prep or result post-processing) is heavy, it might incur overhead in a TEE. Fortunately, LLM inference is typically GPU-bound.
Overall, GPU TEEs represent a significant step forward in enabling confidential computing for AI, largely outweighing the drawbacks for many use-cases. As the technology matures and becomes more widely available, we can expect these limitations to diminish.
Threat Models Addressed by GPU TEEs in LLM Inference
Using GPU Trusted Execution Environments for LLMs directly tackles several important threats and security requirements:
- Insider Threats & Cloud Administrator Access: In a conventional cloud deployment, a rogue admin or compromised hypervisor could peek at customer data or model weights in memory. With a GPU TEE, the confidentiality of both user data and model is protected even from cloud administrators. The memory encryption and isolation means that even if an admin dumps the RAM or GPU memory, they only see ciphertext. For example, if a healthcare query is sent to an LLM in a cloud, the hospital can be confident that no cloud engineer can read that query or its answer in plaintext. Similarly, a company deploying a proprietary LLM can ensure the cloud provider cannot copy the model parameters (addressing IP theft concerns). This is crucial for compliance with data privacy regulations and for companies worried about multi-tenant cloud risk.
- Malicious or Buggy Host Software: Even if the host OS/hypervisor is infected with malware, it cannot compromise the enclave where the LLM runs. The TEE isolates the computation from the rest of the system, so threats like rootkits, keyloggers, or memory scrapers on the host are thwarted. This drastically reduces the attack surface; the model execution is safe even on an untrusted host. This addresses the “evil maid” or compromised infrastructure scenario. It also means edge deployments (like a model running on someone else’s edge device) can be secured – the device owner can’t alter the model or steal data.
- Unauthorized Model Modification: GPU TEEs help ensure model integrity. Through remote attestation, a user can verify that the exact intended model (and version) is running, with no unauthorized modifications. This prevents attacks where someone might swap in a different model or insert a backdoored version. For instance, in the DeepSeek R1 case, a skeptical user can check the enclave measurements to be sure it’s the genuine DeepSeek model provided by the developers, not a trojanized variant. Any change in the model binary or weights would alter the measurement and be detected. This is essential for scenarios where models are distributed by third parties – clients can independently validate what they’re running.
- Data Exfiltration Paths: The enclave model cannot leak data through normal channels because all I/O is tightly controlled and typically encrypted. Developers can ensure that the only outputs are the model’s answers, which are themselves signed. TEEs also block memory scraping and side-channel data leakage to a large extent (though some side-channels like access patterns or timing remain theoretical concerns, they are non-trivial to exploit on encrypted memory systems). By removing mechanisms for covertly exfiltrating data (e.g., the enclave has no access to make arbitrary network calls except through approved channels), GPU TEEs enforce that the model can’t secretly send your prompt elsewhere. In RedPill’s case, the only output is the API response, which is visible to the user and verified – there’s no way for the model instance to, say, copy your input to an untrusted location without breaking the attestation or signature.
- Compliance and Auditability: From a security governance perspective, running LLMs in TEEs addresses requirements for handling sensitive data. All interactions can be logged in attested form, providing an audit trail that the data was processed in compliance with privacy rules. If needed, the attestation logs (quotes, etc.) could be stored (even on a blockchain, as Phala suggests with on-chain registry) to provide long-term verifiable evidence that, for example, a financial report draft was only processed inside a confidential environment. This level of verifiability is new to AI inference and can help in sectors like finance, healthcare, and government where trust and verification are mandated. Nvidia’s attestation services and tooling make it possible to integrate these checks into automated pipelines.
- User Trust in Third-Party Models: Users might distrust an AI model from an external source due to potential hidden behaviors or data handling. While a TEE cannot solve all issues (it can’t guarantee the model’s functional behavior is benign), it does guarantee that what the model does is confined. For example, if a model were maliciously trained to log certain inputs, the TEE would prevent it from actually sending those logs out – the worst it could do is include them in its own output (which the user would see). Moreover, because you can verify the model hash, you can at least ensure you’re running the known version of the model (and not a modified one that has extra Trojan code). In short, TEE = you only have to trust the model’s original developers and the hardware, not the entire execution stack or service operator.
It’s worth noting that GPU TEEs primarily address threats related to confidentiality and integrity of the execution environment. They do not inherently address issues like biases in the model, correctness of the model’s answers, or any malicious logic within the model’s design (those are orthogonal concerns). However, by greatly improving the security of the environment, GPU TEEs lay the groundwork for a zero-trust approach to AI services. In such an approach, one assumes everything (the host, the network, even the model source) could be compromised, and still one is able to get trustworthy results because the hardware enforces the necessary protections and provides proofs of execution. This is a powerful paradigm shift, enabling use-cases like confidential chatbots, secure AI assistants that handle private data, and multi-party ML where participants share a model without exposing their data to each other.
Conclusion
GPU Trusted Execution Environments, spearheaded by NVIDIA’s Confidential Computing on H100 GPUs, are transforming the way we can deploy and consume large language models securely. By anchoring trust in hardware and isolating the entire ML workload, they allow privacy-preserving and verifiable LLM inference at scale – something that was not practical with CPU enclaves alone. We explored how this technology is implemented and used in practice: from the deep integration of NVIDIA H100’s secure boot and attestation with Intel TDX, to real-world frameworks like Phala Network’s confidential cloud (Absolute Zero) that let users “verify, not just trust” AI models. Projects like NearAI’s Private ML SDK are accelerating adoption by providing developer-friendly tools to run LLMs in enclaves, and services like RedPill are offering ready-to-use confidential AI APIs with strong guarantees of data protection and result integrity.
Going forward, as more GPUs (e.g., Blackwell/H200) and cloud providers roll out confidential computing support, we can expect confidential LLM deployment to become a standard option for any scenario involving sensitive data or models. The combination of high-performance computing and high-assurance security means organizations no longer have to choose between leveraging powerful AI models and maintaining confidentiality – they can have both. Secure, privacy-preserving, and verifiable LLMs will enable new applications in finance, healthcare, law, and any field where trust is as important as intelligence. By embracing GPU TEEs, we take a meaningful step toward building AI systems that not only are powerful and useful, but are also worthy of trust in how they handle our data and deliver their results.