
Performance Benchmark Results: SP1 zkVM on TEE H200 GPUs Hits <20% Overhead
2025-03-21
This research was funded by Succinct, whose support made this evaluation possible.
Introduction
If you’re working with zero-knowledge virtual machines (zkVMs) or exploring secure computing, you’ve likely run into the trade-off between performance and privacy. Our latest benchmark study at Phala Network funded by Succinct tackles that head-on, testing SP1 zkVM on NVIDIA H200 GPUs in a Trusted Execution Environment (TEE).
View full benchmark study here, , or keep reading for a quick summary.
Why zkVMs and TEEs?
zkVMs like SP1 (from Succinct) let you write code in familiar languages and automatically generate zero-knowledge proofs—no deep crypto knowledge required. They’re great for verifiable apps like zkEVMs or rollups, but proof generation is computationally heavy, often pushing you to GPUs.
The catch: outsourcing that work can expose your data, since the execution circuit is public. TEEs fix that by isolating the computation, and NVIDIA’s H200 GPUs bring hardware-level encryption to the table.
We wanted to see how this combo holds up in practice!
The Benchmark Setup
Hardware Config: We ran SP1 zkVM on a rig with 2 Intel Xeon Platinum 8558 CPUs (96 cores, TDX enabled), 2TB RAM, and 8 NVIDIA H200 NVL GPUs—each with 141GB memory and 4.8TB/s bandwidth, set to Confidential Computing mode. For the test, we used a VM with 8 CPU cores, 32GB RAM, and a single H200 GPU pass-through.
Software Config: Our dstack SDK (built on private-ml-sdk and dstack) let us run Docker images in the TEE without tweaks. We pulled Succinct’s zkvm-perf codebase, updated via this PR.
For comparison with AWS hardware performance, we used Succinct's existing SP1 benchmark data.
What We Learned
The numbers tell a clear story:
- Overhead Trends: TEE overhead—mostly from encrypted CPU-GPU data transfers—drops below 20% as workload complexity rises. It’s a fixed cost, so longer tasks dilute it. For lighter jobs, pipelining can trim it further.
- Memory Usage: The H200’s 141GB memory was underutilized, averaging 10% across tests. That’s a lot of headroom for bigger circuits or datasets.
- Performance Edge: Against AWS G6 (L4 GPU), the H200 pulls ahead on heavier workloads, balancing TEE security with raw power.
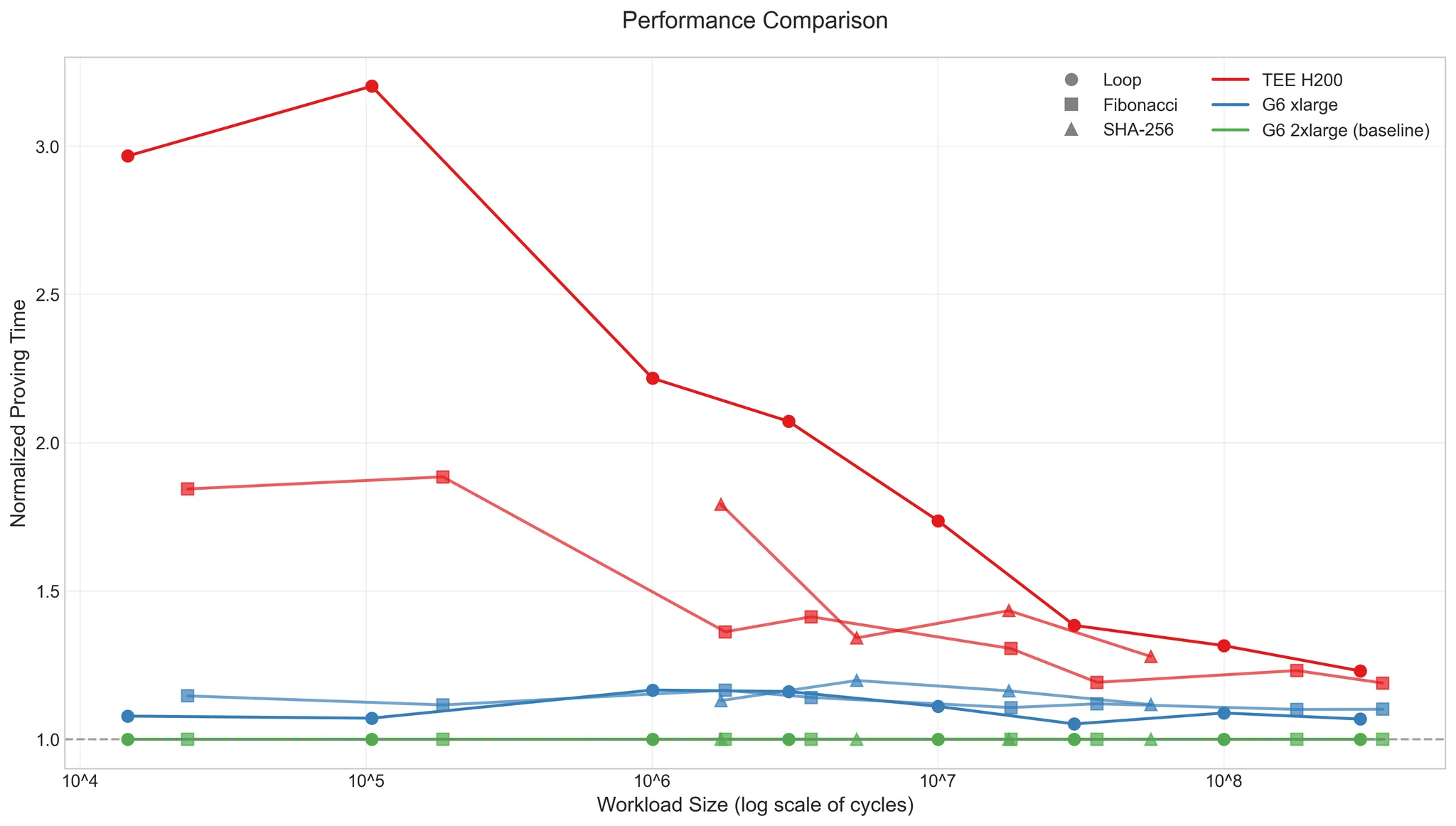
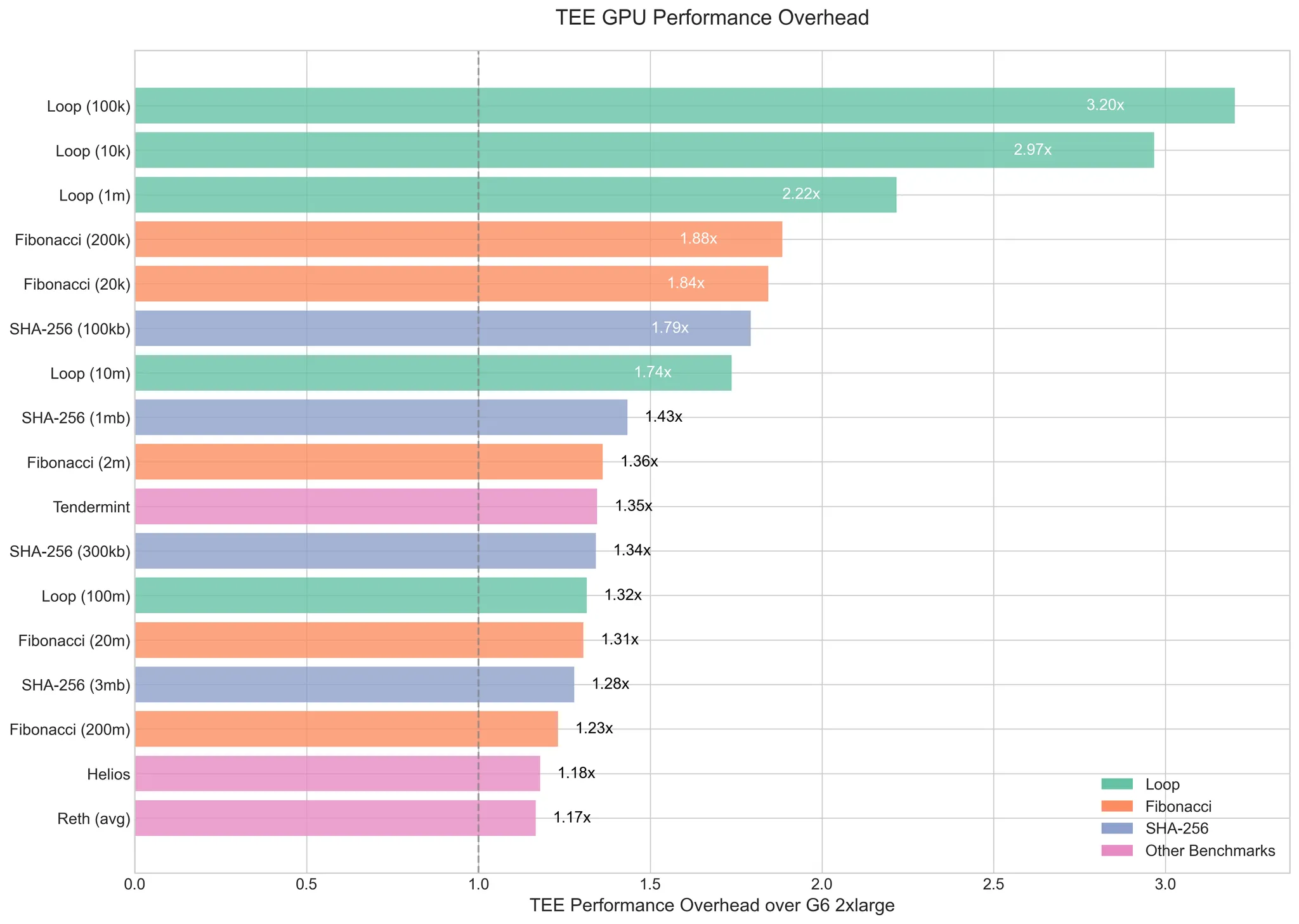
You can dig into the raw data here. The H200’s specs—3341 TFLOPS (INT8), 4.8TB/s bandwidth—make it a beast, and TEE mode doesn’t choke it as much as you’d expect.
Hardware Costs in Context
Here’s a quick look at the H200 versus AWS G6’s L4:
When evaluating the practicality of this approach, cost is an important factor. While the H200 represents the high-end of NVIDIA's GPU offerings, the cost-performance ratio remains favorable for many use cases:
| GPU Model | Memory | Bandwidth | Compute (INT8) | Hourly Cost |
| H200 NVL | 141GB | 4.8TB/s | 3341 TFLOPS | $2.5 |
| L4 (AWS G6) | 24GB | 300GB/s | 485 TFLOPS | $0.805 |
H200 offers approximately 6x the compute power and nearly 6x the memory of the L4, at roughly 3x the cost, making it a cost-effective choice for memory-intensive and computationally demanding zkVM workloads. For many applications, the performance benefits and additional security guarantees justify the increased cost.
What This Means for Developers
For complex stuff—zkEVMs, rollups, or even ML inference—the low overhead makes TEE-enabled H200 a solid pick. The memory headroom hints at supporting larger circuits or multi-workload setups. We’ve seen it work firsthand with SP1, and our research paper dives deeper into TEE GPU behavior.
Phala Cloud’s also prepping GPU H200 support for now you can deploy your CVM in CPU TEE and test our TEE tech stack, you’ll soon be able to spin up zkVM workloads in a TEE without fuss. The dstack SDK on which the Phala Cloud TEE tech is derived from does the heavy lifting, letting you deploy as-is via Docker.
It’s not about selling you something—it’s about giving you tools to experiment with.
- Start by signing up here: Phala Cloud Registration
- Read the full Phala Cloud doc: Phala Cloud Documentation
Use Cases to Explore
Here’s where it gets practical:
- Financial services: Process sensitive transaction data with both privacy and verifiability, enabling compliant yet confidential financial applications.
- Healthcare analytics: Analyze private medical data while providing cryptographic guarantees about the correctness of the analysis without exposing the underlying data.
- Confidential machine learning: Train and run inference on private models and data while providing verifiable guarantees about the model outputs.
- Decentralized identity systems: Process identity verification without exposing personal information, with cryptographic guarantees about the verification process.
The H200’s capacity suggests zkVMs haven’t hit their ceiling yet. If you’re tinkering with bigger ideas, this could be your sandbox.
Wrapping Up
Running SP1 zkVM on TEE-enabled H200 GPUs keeps overhead low and leaves room to grow—good news if you’re building secure, verifiable systems. Phala’s work here (shoutout to Succinct for funding) shows what’s possible when zkVMs meet modern hardware.
Curious? Check the full results or drop by the Phala community to chat about it.
GPU H200 support on Phala Cloud is coming—stay tuned if you want to give it a spin.
