
For people who want to invest and build in LLM, the next great frontier in is not merely about model performance—it's about maximizing economic returns. This comprehensive report synthesizes original benchmarking analyses and profitability analysis through operating on openrouter, emphasizing the strategies to achieve profitable deployments.
Why Efficiency Matters More Than Ever
With AI applications scaling exponentially, efficient inference moves beyond a technical necessity to an economic imperative. Comprehensive benchmarking reveals strategic insights into optimizing model architecture and quantization choices to balance performance and economic viability.
DeepSeek V3: Technical Excellence and Benchmarking
DeepSeek V3 pushes open-source LLM capabilities through an innovative architecture:
- Sparse Mixture of Experts (MoE):
- Total Parameters: 671B, with only 37B actively used per token (approximately 5.5%), dramatically reducing compute and memory overhead.
- Consistently handles high concurrency scenarios, delivering stable throughput crucial for large-scale API deployments.
- Multi-head Latent Attention (MLA):
- Reduces KV cache requirements by 2.5x compared to standard attention mechanisms, essential for long-context efficiency.
- Real Benchmarking data:
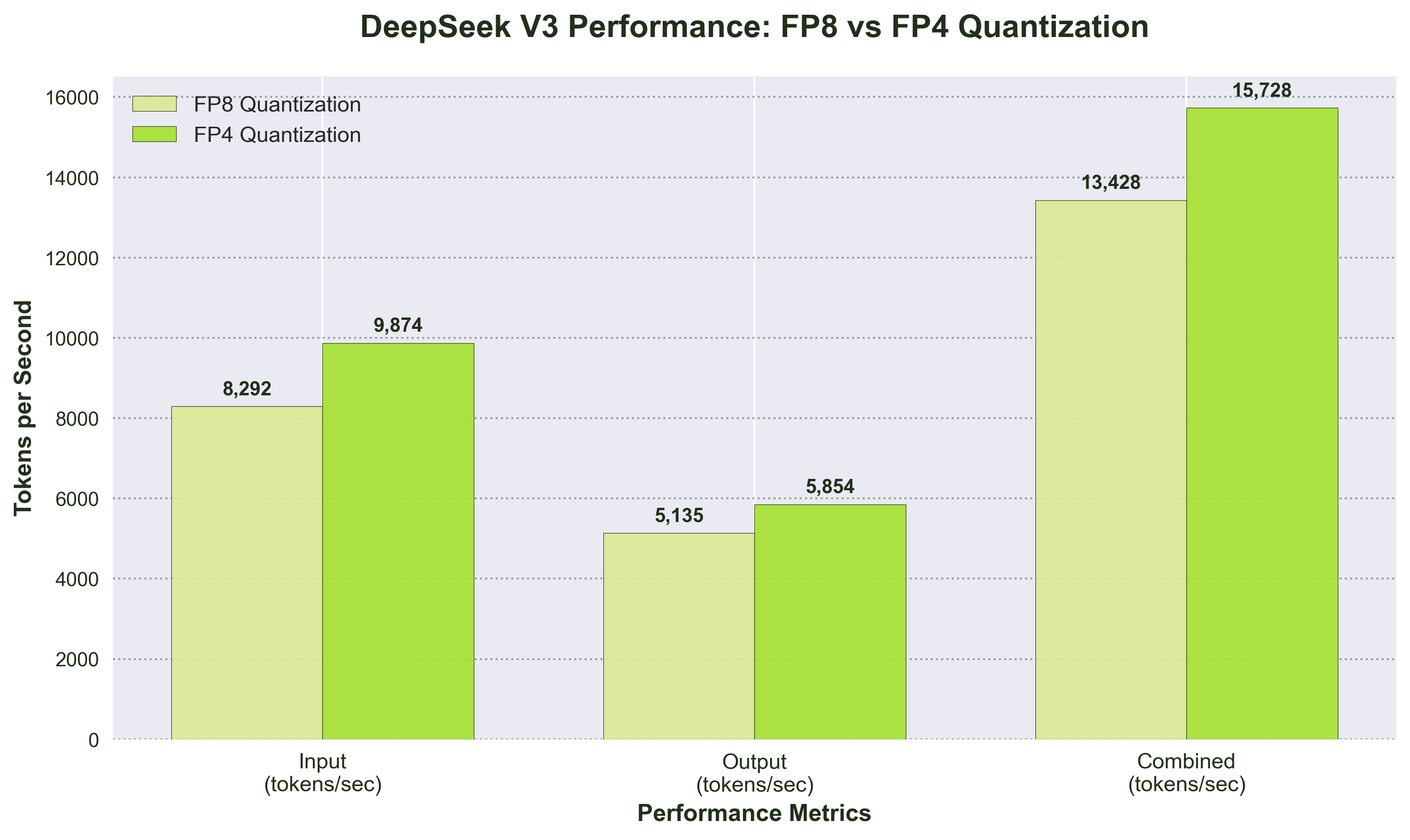
- FP8 Quantization:
- Input: 8,292 tokens/sec, Output: 5,135 tokens/sec, Combined: 13,428 tokens/sec
- Prefix cache hit rate: 96%, indicating exceptional serving infrastructure performance.
- FP4 Quantization:
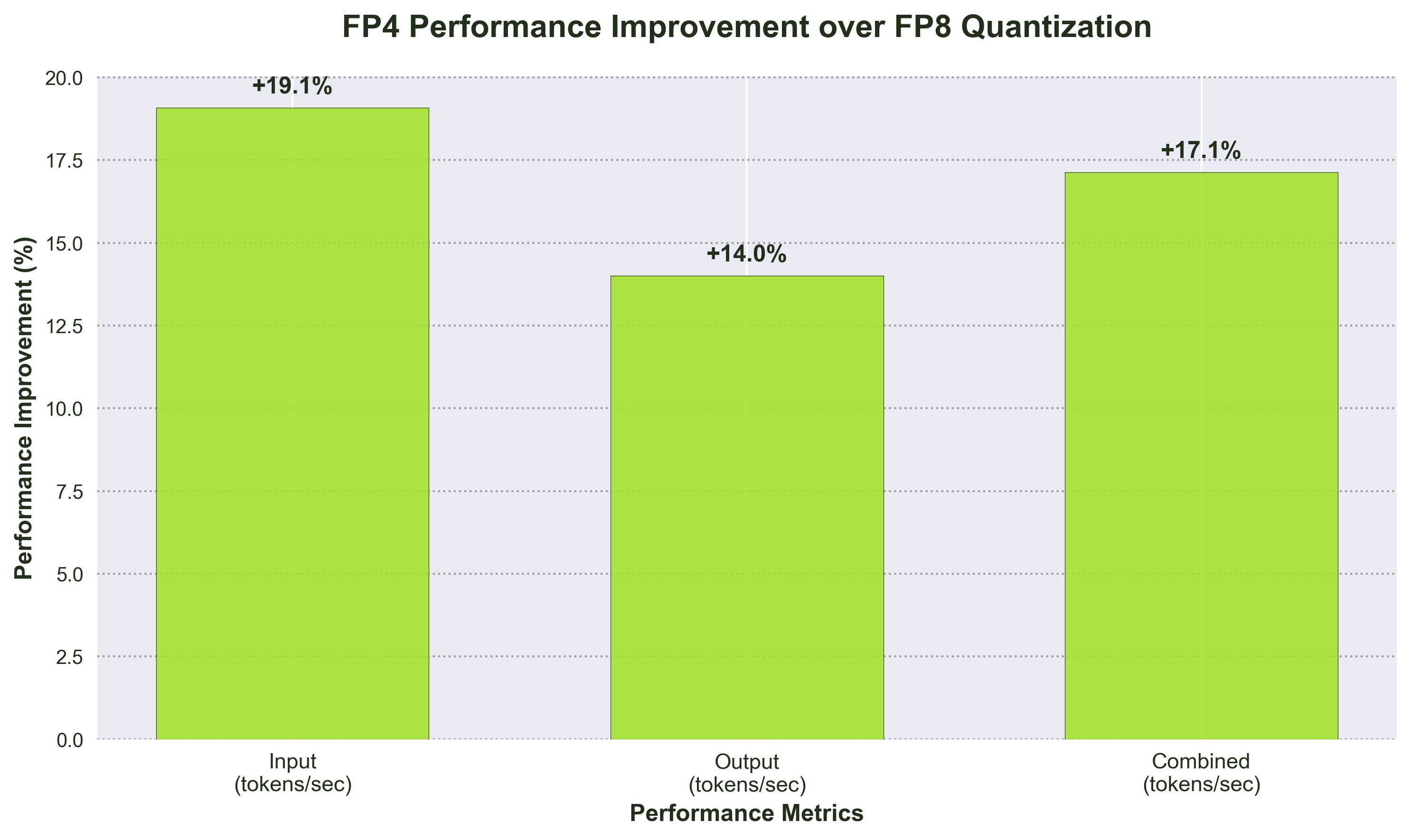
- Input: 9,874 tokens/sec, Output: 5,854 tokens/sec, Combined: 15,728 tokens/sec (17% improvement over FP8)
- Long-context handling (9,000-token prompts): Combined throughput of 11,088 tokens/sec
- High-concurrency handling (1,200 connections): Combined throughput of 10,139 tokens/sec
- FP8 Quantization:
Base on our benchmark test, DeepSeek V3’s innovations position it as economically powerful by balancing throughput, latency, and operational cost.
Market Demand Analysis
These technical strengths have particularly resonated with developers building real-time applications, enterprises requiring high-volume document processing, and research teams conducting long-form analysis, creating a broad user base that values both performance and cost efficiency.
The surge in DeepSeek V3 adoption stems from several compelling use cases:
Enterprise Cost Optimization
As the first open-source model to outperform traditional non-reasoning models from industry giants, It delivers GPT-4-level accuracy and is considered as alternative to premium closed-source models like Google's Gemini 2.0 Pro, Anthropic's Claude 3.7 Sonnet. It is it particularly appealing for developers building production applications with significant usage requirements.
Developer Accessibility
Development teams have particularly embraced DeepSeek V3 for its ability to deliver faster iteration cycles, with reports showing 30% reduced model training time compared to older versions. The model's 128,000 token context window allows developers to build applications requiring extensive context retention, such as long-form document analysis and complex code generation tasks, without experiencing significant performance degradation. Additionally, developers benefit from cleaner API documentation and more intuitive fine-tuning workflows compared to competing models, reducing the technical barriers to implementation.
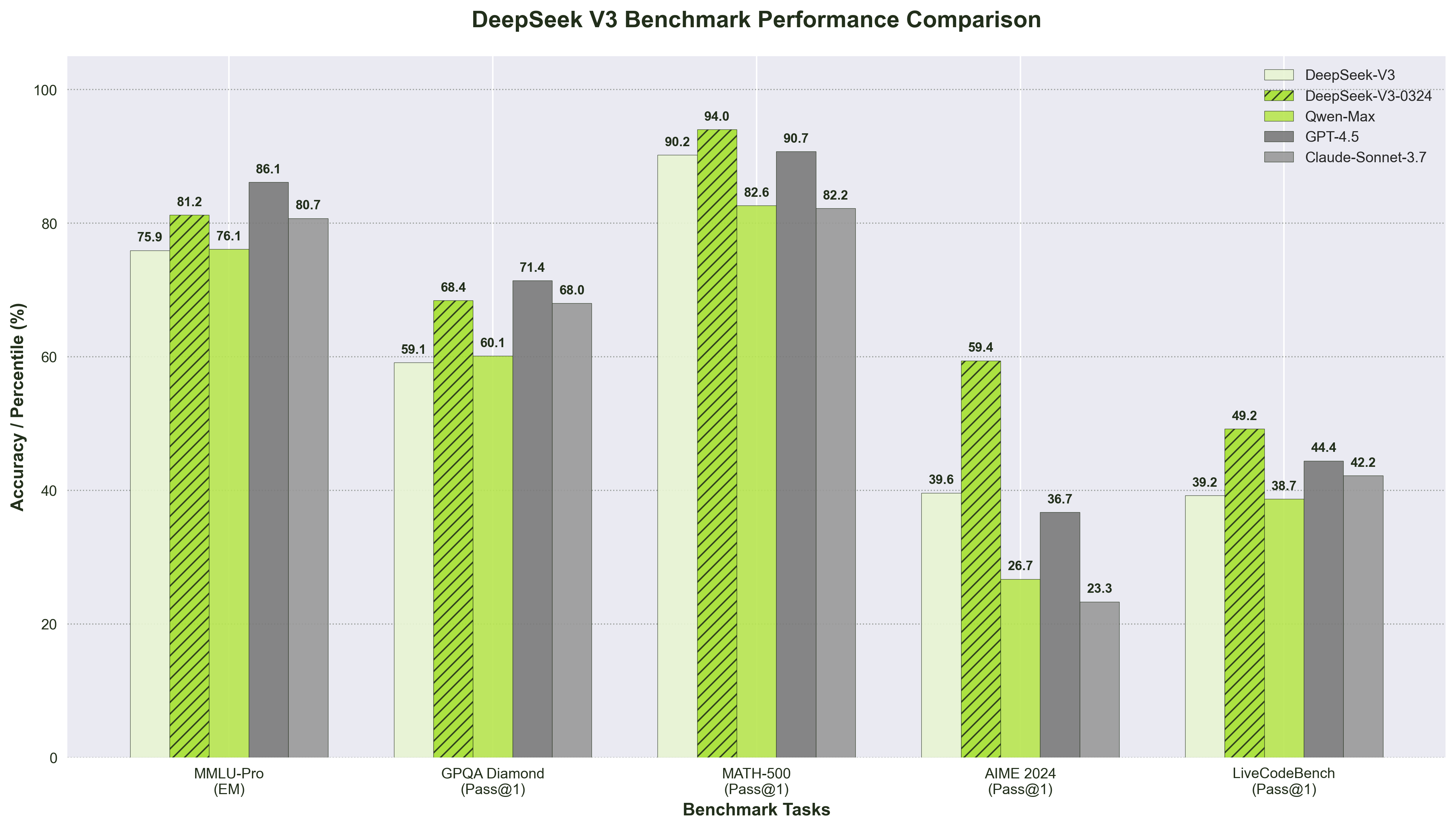
DeepSeek-V3-0324 demonstrates comparable performance comparing with GPT 4.5 and Claude 3.7 Sonnet. Source:Hugging Face
The Profitability Question: Can Running Large Models Generate Real Returns?
For GPU providers considering DeepSeek V3 deployment, the fundamental question remains: Is running these large models actually profitable?
Hardware Requirements Analysis
8-bit Precision (FP8) Configuration
- Memory Requirements: ~671GB total memory (1GB per billion parameters) + 100-200GB for KV Caches (depends on context length, number of concurrent users)
- Recommended Setup: 5-6 H200 GPUs for stable operation
- Baseline Configuration: 6 H200 GPUs for 100 concurrent users with 4,000 token context length
Note: If use 4-bit Precision (FP4) Configuration: Theoretical achieving 50% reduction in hardware requirements
Economic Viability Assessment
Minimum Operational Cost Structure Scenario Assumptions
For a representative deployment supporting 100 concurrent users with 4,000 token context length using 8-bit precision:
- VRAM Requirement: ~775.86GB
- Hardware Configuration: 6 H200 GPUs
We selected these three H200 cost scenarios ($2.50, $2.20, and $1.90 per hour), to identify critical cost thresholds where providers transition from loss-making to profitable operations and understand the economic dynamics driving market sustainability:
- Market Cost Scenario: $2.50/hour/GPU = $360/day baseline cost
- Optimized Cost Scenario: $2.20/hour/GPU = $316.80/day baseline cost
- Low Cost Scenario: $1.90/hour/GPU = $273.60/day baseline cost
Provider Profitability Matrix
| Provider | Daily Revenue (USD) | $2.50/hr P&L | $2.20/hr P&L | $1.90/hr P&L | Profitability Trajectory |
| Novita | $1,675.06 | +$1,315.06 | +$1,358.26 | +$1,401.46 | Consistently High Profit |
| DeepInfra (FP4) | $1,408.53 | +$1,228.53 | +$1,250.13 | +$1,271.73 | Consistently High Profit |
| Lambda | $446.27 | +$86.27 | +$129.47 | +$172.67 | Marginal to Solid Profit |
| Cent-ML | $319.77 | -$40.23 | +$2.97 | +$46.17 | Loss to Break-even to Profit |
| Parasail | $303.07 | -$56.93 | -$13.73 | +$29.47 | Loss to Marginal Profit |
| Kluster | $294.99 | -$65.01 | -$21.81 | +$21.39 | Loss to Marginal Profit |
| InferenceNet | $283.61 | -$76.39 | -$33.19 | +$10.01 | Loss to Break-even |
| BaseTen | $265.23 | -$94.77 | -$51.57 | -$8.37 | Significant to Minimal Loss |
| Nebius | $234.50 | -$125.50 | -$82.30 | -$39.10 | Persistent Loss |
| GMICloud | $201.98 | -$158.02 | -$114.82 | -$71.62 | Persistent Loss |
| Fireworks | $149.01 | -$210.99 | -$167.79 | -$124.59 | Persistent Loss |
| Hyperbolic | $114.05 | -$245.95 | -$202.75 | -$159.55 | Persistent Loss |
| Together | $102.47 | -$257.53 | -$214.33 | -$171.13 | Persistent Loss |
| SambaNova | $97.04 | -$262.96 | -$219.76 | -$176.56 | Persistent Loss |
Note: All figures are estimated based on OpenRouter's public metrics for research purposes only
DeepInfra's 4-bit precision implementation potentially reduces minimum costs to ~$180/day
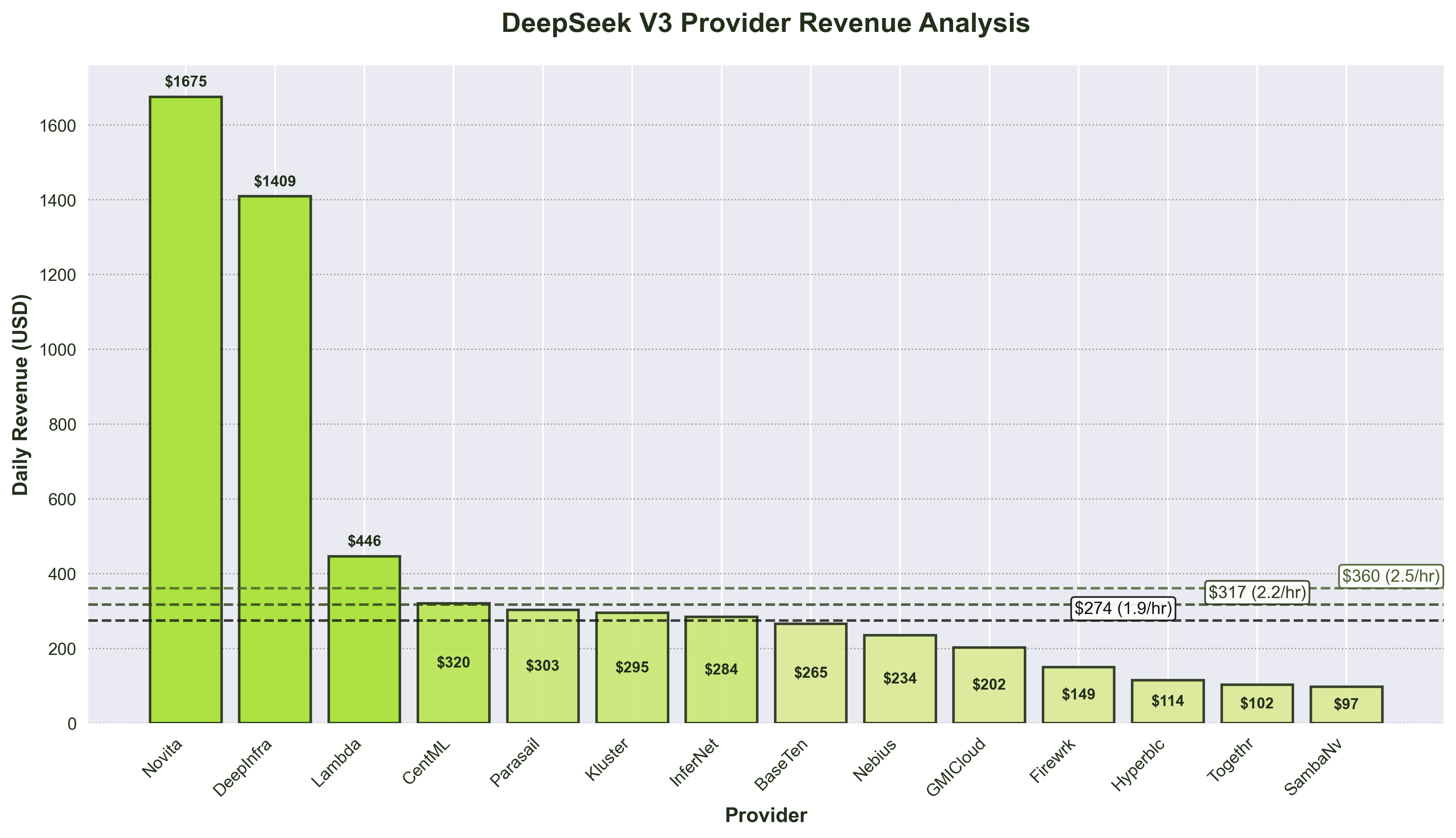
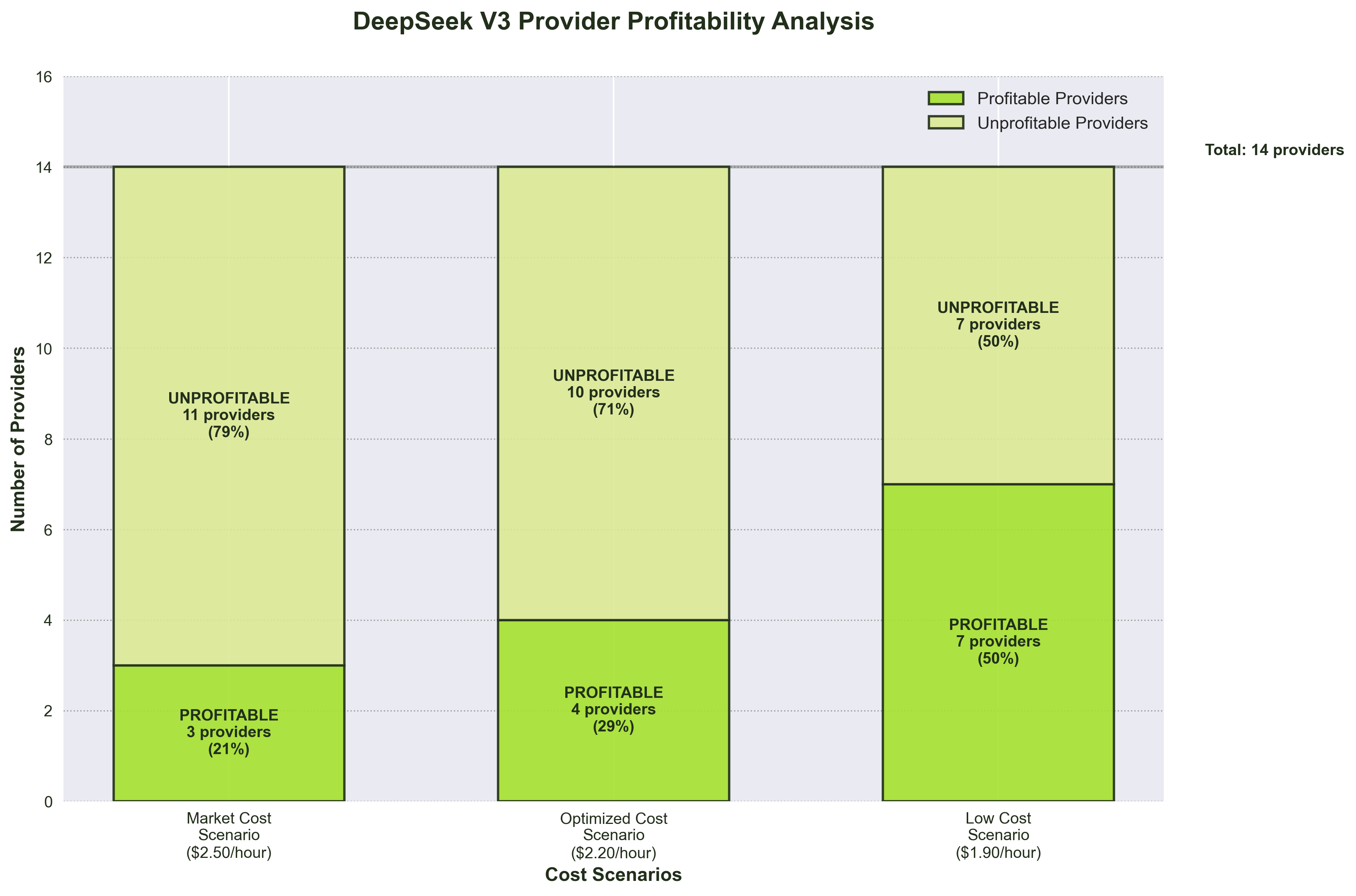
Profitability Analysis Summary:
- Market Cost Scenario ($2.50/hour): Only 21% of providers (3 out of 14) achieve profitability, while 79% of providers operate at losses ranging from $40-263 daily.
- Optimized Cost Scenario ($2.20/hour): It shows improvement with 28% of providers (4 out of 14) can profit , with 72% still operating at losses ranging from $8-220 daily.
- Low Cost Scenario ($1.90/hour): Market dynamics fundamentally shift with 50% of providers (7 out of 14) achieving profitability, while the remaining 50% operate at reduced losses ranging from $39-177 daily.
Strategic Motivations Behind Loss-Leading Operations
These findings reveal a stark economic reality: despite DeepSeek V3's technical excellence and robust market demand, the majority of providers struggle to achieve sustainable profitability under prevailing market conditions. Even in the optimized low-cost scenario ($1.90/hour), 50% of providers continue experiencing operational losses. This paradox raises fundamental questions about the strategic motivations driving continued investment in unprofitable operations and the long-term considerations that may justify short-term financial sacrifices.
- Surplus Capacity Monetization:Many providers possess excess computational resources, adopting "better than nothing" strategies to generate revenue rather than maintaining idle hardware.
- Long-Term Market Positioning:Forward-thinking providers view current losses as investments in market share development and capability demonstration, anticipating future pricing power as market dynamics mature.
- Technical Optimization Advantages:Advanced providers leverage proprietary optimization techniques including custom inference optimizations, efficient batching strategies, advanced caching mechanisms, and hardware-specific tuning capabilities.
Market Dynamics and Customer Behavior
Artificial Analysis's research demonstrates that while higher-performance models typically command premium pricing, open-source models exhibit fundamentally different market dynamics. It becomes essential to examine the underlying forces that systematically suppress pricing below economically sustainable thresholds. Current market analysis reveals several interconnected factors driving this unsustainable pricing structure:
- Open-Source - Free Pricing Expectations: Customers expect significantly lower pricing for open-source models, creating an expectation of "free" or near-free access regardless of operational complexity. Free tier usage substantially exceeds paid adoption on OpenRouter, with free versions processing 126B weekly tokens compared to 101B for paid tiers
- Customer Segmentation Challenges: The primary user base consists of cost-conscious developers and researchers rather than enterprise customers with higher willingness to pay
- Service Homogenization: Multiple providers offering essentially identical services create intense price competition and a race-to-the-bottom pricing dynamic
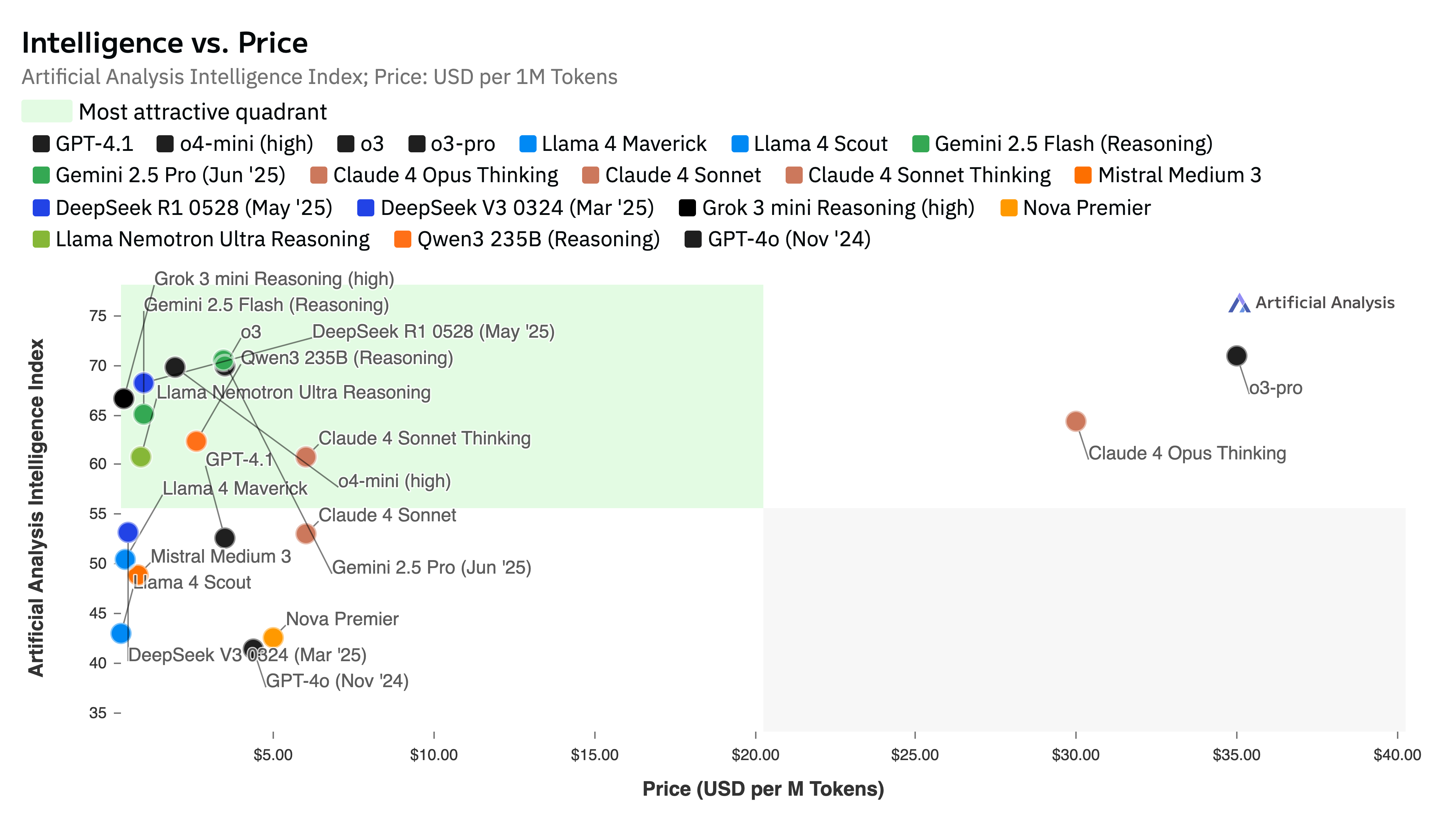
source: Artificial Analysis
For users, open-source models consistently deliver the highest ROI and demonstrate strong Product-Market Fit (PMF), as evidenced by robust demand metrics (126B weekly tokens on free tiers alone) and the market's behavior where customers consistently choose open-source alternatives despite premium closed-source options. High-performance models like DeepSeek V3 have successfully addressed a fundamental market need: high-performance AI capabilities at accessible price points.
However, this user-centric value creation creates a fundamental paradox for service providers. The persistent willingness of providers to operate at losses, combined with the intense competition driven by service commoditization, demonstrates that while open-source models deliver exceptional value to customers, providers face a market dynamic where strong customer demand does not translate into sustainable profitability. This disconnect between user satisfaction and provider economics highlights the challenging monetization landscape in the open-source AI inference market.
Strategic Recommendations for Sustainable Profitability
Compare Multiple Precision Options
Our previous analysis revealed that even with FP4 quantization, market demand remains robust, suggesting that DeepSeek V3's well-engineered architecture maintains acceptable performance levels despite the precision reduction. This finding is particularly significant given that DeepInfra stands out as the only major provider offering FP4 precision on OpenRouter while most competitors deploy FP8 versions, yet DeepInfra maintains strong profitability with $1,408.53 daily revenue—demonstrating that the theoretical 50% hardware cost reduction from FP4 quantization translates into real competitive advantages without compromising market appeal or revenue generation.
FP8 Implementation
- Recommended for accuracy-sensitive applications
- Balanced approach between performance and resource utilization
- Suitable for general-purpose deployments requiring high reliability
FP4 Deployment
- Optimal for cost-conscious operations
- 50% hardware requirement reduction with 17% performance improvement
- Acceptable quality trade-offs for most applications
- Significantly improved profit margins potential
Operational Excellence Means Both Technically and Strategically
For LLM providers operating in the highly commoditized open-source model landscape, achieving sustainable profitability requires a comprehensive approach that combines operational excellence with strategic market positioning
Continuous improvements in core Infrastructure Capabilities:
- Continuous performance optimization through advanced monitoring and alerting systems
- Efficient resource allocation strategies leveraging automated deployment pipelines
- Custom optimization and hardware tuning expertise that enables superior margins
- Advanced caching mechanisms and hardware-specific optimizations
Business Model Innovation:
- Selective Deployment: Focus on model configurations with proven profitability metrics
- Service Differentiation: Competition on reliability, latency, specialized features and value-added services
- Enterprise-focused offerings with SLA guarantees and dedicated support tiers
- Custom optimization and consulting services leveraging proprietary expertise
- Specialized industry solutions addressing specific vertical requirements
The future of AI inference will favor providers who strategically balance technical innovations with operational efficiency and economic viability. Success requires mastering the convergence of and sustainable business model development to drive profitability in the evolving AI economy.
- https://arxiv.org/abs/2412.19437
- https://www.prompthackers.co/compare/deepseek-v3/gpt-4
- https://arxiv.org/pdf/2412.19437.pdf
- https://encord.com/blog/deepseek-ai/
- https://adasci.org/deepseek-v3-explained-optimizing-efficiency-and-scale/
- https://www.deeplearning.ai/the-batch/deepseek-v3-redefines-llm-performance-and-cost-efficiency/
- https://community.aws/content/2rJj1WkztSfYwVfsIibhWxeqMf1/four-unique-takeaways-from-deepseek-v3?lang=en
- https://ppl-ai-file-upload.s3.amazonaws.com/web/direct-files/attachments/31964595/1c9626b9-15a2-4fa2-8b74-110552bee126/paste.txt
- https://www.byteplus.com/en/topic/384490
- https://huggingface.co/papers/2412.19437
- https://huggingface.co/docs/transformers/main/model_doc/deepseek_v3
- https://www.byteplus.com/en/topic/382612
- https://api-docs.deepseek.com/news/news1226
- https://arxiv.org/html/2502.03688v1
- https://www.gosearch.ai/blog/what-is-deepseek-ai-should-other-llms-be-worried/
- https://www.reddit.com/r/OpenAI/comments/1hnngrk/deepseekv3_is_hands_down_better_than_4o_as_an_llm/
- https://zilliz.com/blog/why-deepseek-v3-is-taking-the-ai-world-by-storm
- https://artificialanalysis.ai/providers/deepseek
- https://arxiv.org/html/2412.19437v1
- https://bytesizeddesign.substack.com/p/how-deepseek-v3-brings-open-source
- https://docsbot.ai/models/compare/deepseek-v3/gpt-4
- https://artificialanalysis.ai/
- https://huggingface.co/deepseek-ai/DeepSeek-V3-0324